Analiza przyczyn źródłowych (RCA): Kompleksowy przewodnik dla zespołów inżynieryjnych, QA i biznesowych

Analiza przyczyn źródłowych (Root Cause Analysis – RCA) to jedno z najskuteczniejszych narzędzi, jakie możesz wprowadzić do zespołu produktowego lub inżynieryjnego. Pozwala ona przestać “gasić pożary i zacząć naprawdę rozumieć, skąd biorą się problemy z jakością, opóźnienia oraz utrata klientów.
„Definicja systemu legacy mówi, że to system bez testów automatycznych. Można by uznać, że to jest przyczyną problemów z jakością. Moim zdaniem to tylko symptom – objaw problemów z jakością procesu, a nie samego kodu”.
RCA służy właśnie po to, by zajrzeć pod powierzchnię.
Czym jest RCA (Root Cause Analysis)?
RCA (Root Cause Analysis) to metoda analityczna, której celem jest znalezienie głębokiej przyczyny problemu – „korzenia”, z którego wyrastają widoczne błędy i awarie. Nie chodzi w niej o szukanie winnych („kto zawalił?”), ale o odpowiedzi na pytania:
- Dlaczego system lub proces w ogóle pozwolił na pojawienie się tego błędu?
- Co zawiodło w naszym sposobie pracy, komunikacji, testowaniu lub projektowaniu?
„RCA, czyli Root Cause Analysis, to ćwiczenie – w skrócie analiza kluczowego powodu. To narzędzie do szukania źródła problemu”.
Dobrze przeprowadzona analiza RCA:
- kończy się konkretnymi zmianami w procesie,
- nie zatrzymuje się na jednorazowym błędzie (typu „Krzysiek zapomniał”),
- jest powtarzalna i udokumentowana.
Kiedy stosować RCA w projekcie IT?

RCA nie jest narzędziem do analizy każdego drobnego błędu. To „ciężki kaliber”, po który warto sięgnąć, gdy:
- dojdzie do poważnego incydentu na produkcji (awaria systemu, utrata klienta, katastrofa jakościowa),
- problem powtarza się regularnie w tym samym obszarze systemu,
- musisz zmienić proces, a nie tylko wypuścić szybką poprawkę (hotfix),
- widzisz, że całe zespoły działają w trybie naprawczym zamiast rozwijać produkt.
Obrazowy przykład:
„Wyobraźmy sobie taką sytuację. Trwa demo dla klienta. Sektor B2B, idziemy tam sprzedać naszą aplikację. Piękna prezentacja i nagle – Internal Server Error”.
To jest właśnie ten moment, w którym warto powiedzieć: dobrze, czas na RCA.
Inne typowe wyzwalacze:
- po dużym wdrożeniu, które „zepsuło połowę systemu”,
- gdy działy wsparcia lub sprzedaży ciągle zgłaszają: „klienci w kółko raportują to samo”,
- gdy Product Owner słyszy od klienta: „to już trzeci raz”.
| Powtarzające się problemy często wskazują na głębsze luki w procesach lub jakości. Nasze usługi projektów adresują te wyzwania, łącząc analizę przyczyn źródłowych, modernizację i testy automatyczne, aby problemy przestały wracać. |
Jak wygląda dobra analiza RCA krok po kroku?
Kluczowa zasada: RCA to nie polowanie na czarownice. To moderowana rozmowa, w której ludzie mają bezpieczną przestrzeń, by powiedzieć: „Zapomniałem, przeoczyłem to, nie wiedziałem”.
„Jeśli jesteśmy w organizacji, gdzie środowisko jest bezpieczne, możemy otwarcie powiedzieć: Krzysiek i Adam zapomnieli, przeoczyli to. I to jest w porządku. To nie oznacza ‘zwolnijmy ich’. Bo wtedy nigdy nie dotrzemy do prawdziwej przyczyny źródłowej”.
RCA to nie audyt – to ćwiczenie ze wspólnej odpowiedzialności.
Etapy RCA:
Zbierz materiały:
- zgłoszenia błędów z produkcji (np. z Jiry),
- logi, zrzuty ekranu, zgłoszenia od klientów,
- informacje o tym, kto zareagował, kiedy i w jaki sposób.
„Zacząłbym od błędów. Skąd się biorą? Zebrałbym zgłoszone błędy, przeanalizował je i pogrupował. Może się okazać, że niektóre części systemu są bardziej podatne na błędy lub ważniejsze dla użytkowników – dlatego to je zgłaszają”.
Wyznacz moderatora:
- osoba ta prowadzi rozmowę i zadaje pytania,
- dopytuje „dlaczego?” na wiele różnych sposobów,
- dba o to, by spotkanie nie zmieniło się w szukanie winnych.
„Liczy się umiejętność facylitacji i zadawania pytania ‘dlaczego’ na milion sposobów”.
Analizuj trzema ścieżkami:
- Dlaczego błąd w ogóle wystąpił?
- Jak zareagowaliśmy?
- Jak naprawiliśmy błąd i czy to wystarczy?
Sformułuj wnioski procesowe:
- co zmienimy w DoR, DoD, standardach, architekturze, testach czy refaktoryzacji.
Wdróż i egzekwuj:
- zaktualizuj proces (tablice, przepływ pracy, Definition of Done/Ready),
- upewnij się, że wnioski nie zostaną tylko ładnym dokumentem w Confluence.
Jak szukać „dlaczego”? Trzy ścieżki RCA

1. Dlaczego błąd wystąpił? – Refinement i Definition of Ready
Przykład: formularz, który pozwala pominąć pole wymagane przez backend.
„Dlaczego mamy ten błąd? Ponieważ pole w formularzu nie jest wymagane, a backend potrzebuje tej wartości do dalszych obliczeń. Dlaczego nie jest wymagane? Bo tak było od zawsze. Nigdy nie było to kluczowe. Dlaczego nie wymusiliśmy tej zmiany w formularzu? Bo Krzysiek i Adam zapomnieli i to przeoczyli”.
W tym miejscu łatwo o błąd:
„Stąd możemy szybko przejść do wniosku: ‘zwolnijmy ich’. To by oznaczało, że nigdy nie dotrzemy do prawdziwej przyczyny, dlatego tego nie polecam”.
RCA idzie głębiej:
„Skąd mieli o tym wiedzieć? Nie było scenariusza, który by to opisywał. Gdybyśmy mieli dobry refinement, nie zapomnielibyśmy o ważnych scenariuszach. Ale ograniczyliśmy refinement, bo nie chcieliśmy długich spotkań”.
Wniosek procesowy:
- lepszy refinement,
- dodatkowe pytania o scenariusze i ścieżki błędów wpisane w Definition of Ready (DoR),
- nawyk myślenia scenariuszami testowymi: „co może pójść nie tak?”.
„Rozwiązanie prawie zawsze leży w procesie, bo to niemal zawsze wina procesu”.
2. Jak zareagowaliśmy na błąd? – Definition of Done i CTA
Krótka historia:
„Nasz handlowiec, Jakub, napisał na kanale: ‘Nie mogę przejść przez formularz, nie mogę dokończyć demo, potrzebuję pomocy’. Okazało się, że trafił na błąd, z którego mógł wyjść – wystarczyło wypełnić pole daty rozpoczęcia. Ale tego nie zrobił, bo komunikat ‘Internal Server Error’ nie mówił, co jest nie tak”.
To jest druga ścieżka RCA: reakcja systemu i ludzi.
- Czy komunikat o błędzie pomógł użytkownikowi rozwiązać problem?
- Czy pojawiła się instrukcja (CTA) mówiąca, co zrobić dalej?
- Czy dział wsparcia wiedział, co odpowiedzieć?
„Wystarczyłoby dodać do Definition of Done zasadę, że każdy błąd musi mieć wezwanie do działania (call to action). Dzięki temu system powie użytkownikowi, co ma zrobić w następnej kolejności”.
I kluczowy niuans:
„Można powiedzieć: product owner lub analityk nie określili, co dokładnie ma być w tej wiadomości. Ale jeśli mamy to w Definition of Done, to nawet gdy PO czy analityk jest chory lub niedostępny – deweloper i tak przygotuje chociażby prosty tekst, który będzie zawierał CTA. W rezultacie nie stracilibyśmy klienta”.
Wniosek procesowy: Dodajemy do Definition of Done: 👉 „Każdy komunikat o błędzie musi zawierać jasny opis + wezwanie do działania (call to action)”.
| Pomocne komunikaty o błędach i CTA wymagają empatii i wyczucia UX. Dlatego w naszym procesie budowania produktów cyfrowych uwzględniamy wnioski z RCA w Definition of Done. Dzięki temu mamy pewność, że każdy komunikat czy stan systemu jest jasny i użyteczny. |
3. Jak naprawiliśmy błąd? – Dane historyczne i trwałość rozwiązania
Trzecia ścieżka: czy poprawka jest kompletna?
„Ustawiliśmy pole jako wymagane i gotowe, prawda? Ale czy to wystarczy? Nie. Dlaczego? Bo mamy 1 217 307 użytkowników, którzy już przeszli przez ten formularz. Gdy spróbują wygenerować raport, nadal otrzymają błąd”.
Klasyczny przypadek:
- poprawka (hotfix) działa dla nowych danych,
- ale dane historyczne pozostają niespójne.
„Doszlibyśmy do punktu, w którym do DoR należy dodać pytanie: ‘Czy po tej zmianie musimy zadbać o dane historyczne?’”.
Wniosek procesowy: Dodajemy do Definition of Ready pytanie techniczne: 👉 „Czy ta zmiana wymaga działań na danych historycznych (migracja, przeliczenie, wzbogacenie)?”.
Przykładowe wyniki RCA – tabela
| Problem znaleziony w RCA | Przyczyna źródłowa | Zmiana w procesie (DoR / DoD / praktyki) |
|---|---|---|
| Pole w formularzu nie jest wymagane, a backend go potrzebuje | Brak omówienia scenariusza na refinemencie; ucinanie dyskusji „dla oszczędności czasu” | DoR: pytania o scenariusze i walidacje; praca na przykładach i przypadkach brzegowych |
| Komunikat Internal Server Error bez wyjaśnienia | Domyślny, generyczny komunikat; brak standardu obsługi błędów | DoD: „Każdy błąd musi mieć CTA”; minimalny standard treści |
| Błąd generowania raportu dla starych rekordów | Hotfix naprawił tylko nowe rekordy; pominięcie danych historycznych | DoR: „Czy zmiana wymaga działań na danych historycznych?”; zadanie techniczne na migrację danych |
| Literówka w typie produktu („soop” zamiast „soup”) | Ręczne wpisywanie ciągów znaków; brak walidacji / typów wyliczeniowych | Wprowadzenie typów wyliczeniowych (enums), walidatorów i linterów; code review skupione na zahardkodowanych wartościach |
| Brak testu, który wyłapałby błąd | Brak nawyku projektowania testów na etapie DoR; brak automatyzacji | Wprowadzenie strategii testów automatycznych; DoD: „testy zdefiniowane i/lub zaimplementowane”; testy regresji dla kluczowych przepływów |
Jak dzięki RCA rozmawiać z biznesem o pieniądzach?
„W moim przypadku straciliśmy klienta, którego wartość (lifetime value) wynosiła prawie półtora miliona dolarów. Przez mały błąd w prezentacji demo. Zabrakło podstawowej rzeczy – jasnego wezwania do działania w komunikacie o błędzie.
Biznes lubi pieniądze i chce widzieć wpływ naszych działań na wynik finansowy”.
To pozwala zbudować konkretną narrację: błąd techniczny → doświadczenie użytkownika → utrata klienta → konkretny koszt (LTV itp.).
Inny przykład:
„Może być tak, że sklep internetowy nie działa. Niedostępność usługi to konkretny koszt. Możesz pokazać biznesowi: w Black Friday straciliście tyle i tyle pieniędzy, bo sklep nie był gotowy na taki ruch”.
Oraz o poprawkach (rework):
„Załóżmy, że mamy trzy, cztery, pięć zespołów deweloperskich, a jeden lub dwa z nich ciągle łatają błędy. Zobacz, ile to kosztuje. Możesz to przeliczyć na dolary. Sprawdź, ile mocy przerobowej marnujemy na naprawianie błędów. Te statystyki pomagają w rozmowie z biznesem: ‘To nie jest w porządku. Musimy spłacić dług techniczny. To będzie kosztować, ale się opłaci, bo możemy to przeliczyć na konkretne kwoty’”.
Jak zamienić to na liczby:
- liczba godzin w sprincie poświęcona na poprawki (rework) vs nowe funkcje,
- koszt utraconych szans (przestoje, nieudane dema),
- LTV utraconych lub sfrustrowanych klientów.
Dzięki RCA nie idziesz do biznesu z argumentem „chcemy testów, bo lubimy jakość”, ale mówisz:
„Oto konkretne incydenty, ich przyczyny procesowe oraz ich koszt w dolarach. A oto konkretne zmiany, które pozwolą nam uniknąć tych kosztów w przyszłości”.
Jaka jest rola testów automatycznych w RCA i ograniczaniu poprawek?
„Definicja systemu legacy mówi, że to system bez testów automatycznych. Można by uznać, że to jest przyczyną problemów z jakością. Moim zdaniem to objaw słabej jakości procesu, a nie samego kodu”.
Analiza RCA bardzo często kończy się wnioskiem:
„Testy by temu zapobiegły”.
Testy jako suma kontrolna
„Testy są jak suma kontrolna. System rośnie latami, nie pamiętamy już każdej zasady, ale testy automatyczne i testy regresji nas chronią.
Jeśli za miesiąc zmienimy logikę naliczania kuponów, test zaświeci się na czerwono, jeżeli stara logika (np. 10% rabatu) zostanie naruszona. Ktoś musi wtedy celowo zmienić test na 15%”.
Testy a poprawki (rework)
„Dlaczego biznes potrzebuje testów? Aby ograniczyć poprawki – liczbę błędów i zadań, które wracają do programistów. Kończymy sprint, wdrażamy, a potem wraca feedback z błędami i musimy poprawiać”.
Jeśli więc po kolejnych analizach RCA widzisz, że:
- „test w tym miejscu by to wykrył”,
- „tutaj też test by pomógł”, masz teraz mocny argument: testy nie są „inżynieryjnym luksusem”. To inwestycja w ograniczanie poprawek i bezpieczniejsze wdrożenia.
RCA a dług techniczny: Tidy First i ewolucyjna refaktoryzacja
RCA często ujawnia, że prawdziwym problemem nie jest „ten konkretny błąd”, ale:
- silne powiązania (coupling) między modułami,
- czytelność kodu na poziomie „archeologii”,
- brak separacji odpowiedzialności i możliwości testowania.
Możesz więc zapytać:
„Jak zacząć spłacać dług techniczny bez wstrzymywania prac nad nowymi funkcjami?
Jeśli nie możemy lub nie chcemy przepisywać systemu od zera, a jednocześnie nie chcemy zostawiać go w obecnym stanie, zostaje nam jedna opcja: ewolucja obecnego rozwiązania, czyli stopniowa (przyrostowa) refaktoryzacja”.
O powiązaniach (coupling):
„Większość problemów w tworzeniu oprogramowania wiąże się z powiązaniami. Jeden moduł jest złączony z innym, mimo że nie powinien. Jeśli kod rabatowy nie działa, nie możesz zapłacić za koszyk.
Aby pozbyć się tych powiązań, musisz refaktoryzować moduł po module, wydzielać je. To trudne, ale rozwijając obecne rozwiązanie, wprowadzamy mniejsze zmiany i bardzo szybko otrzymujemy informację zwrotną”.
O zasadzie Tidy First:
„Polecam książkę ‘Tidy First’. Główna idea: deweloper nieznacznie poprawia kod podczas wprowadzania zmian – nie po sobie, ale przed sobą. To małe kroki, dzięki którym system jest dziś nieco lepszy niż wczoraj”.
RCA to Twój radar, który pokazuje:
- gdzie dług techniczny boli najbardziej,
- których obszarów należy dotknąć w pierwszej kolejności,
- które praktyki (refaktoryzacja, typy wyliczeniowe, modułowość) należy sformalizować.
| Odzwierciedla to naszą usługę ratowania projektów – pomagamy klientom przejść od gaszenia pożarów do proaktywnej ewolucji. Sesje RCA często wskazują krytyczne punkty długu technicznego, a nasze zespoły zamieniają je w uporządkowane plany refaktoryzacji, które redukują ryzyko bez przerywania dostarczania nowych funkcji. |
Jak mierzyć efekty RCA? – przydatne metryki
„Zawsze mierz efekty i dbaj o to, by metryki były widoczne. Czy to Lead Time, metryki DevOps, liczba błędów (która może wzrosnąć, gdy zaczniemy naprawiać rzeczy i odkrywać nowe części systemu), czy pokrycie testami.
Niektóre metryki to dane o procesie, ale powinniśmy też mierzyć rezultaty (outcome) – to, jak użytkownicy reagują na nasze działania”.
Jakie metryki połączyć z RCA?

- Lead Time (czas od pomysłu/błędu do wdrożenia na produkcję),
- Liczba błędów (szczególnie w tym samym obszarze),
- Pokrycie testami,
- Rezultaty (Outcome) (reakcje użytkowników, NPS, retencja),
- Moce przerobowe zespołu poświęcone na poprawki (rework) vs nowe funkcje,
- Zadowolenie zespołu / współczynnik obaw.
„Możemy zacząć od prostej ankiety: ‘Czy boisz się wdrażać zmiany w piątek?’. To pomaga nam sprawdzić, czy dzięki zmianom w procesie jest ‘lepiej niż wczoraj’”.
I bardzo ludzka myśl na koniec:
„Projekty legacy są duże, bezwładność systemu jest ogromna. Frustruje mnie to, że chciałbym być pięć kroków do przodu, a my wciąż gasimy pożary.
Wtedy pomagają metryki. Dzięki nim widzisz: hej, jest lepiej niż było wczoraj. Może powoli, może nieidealnie, ale lepiej niż wczoraj”.
Najczęstsze błędy w analizie RCA
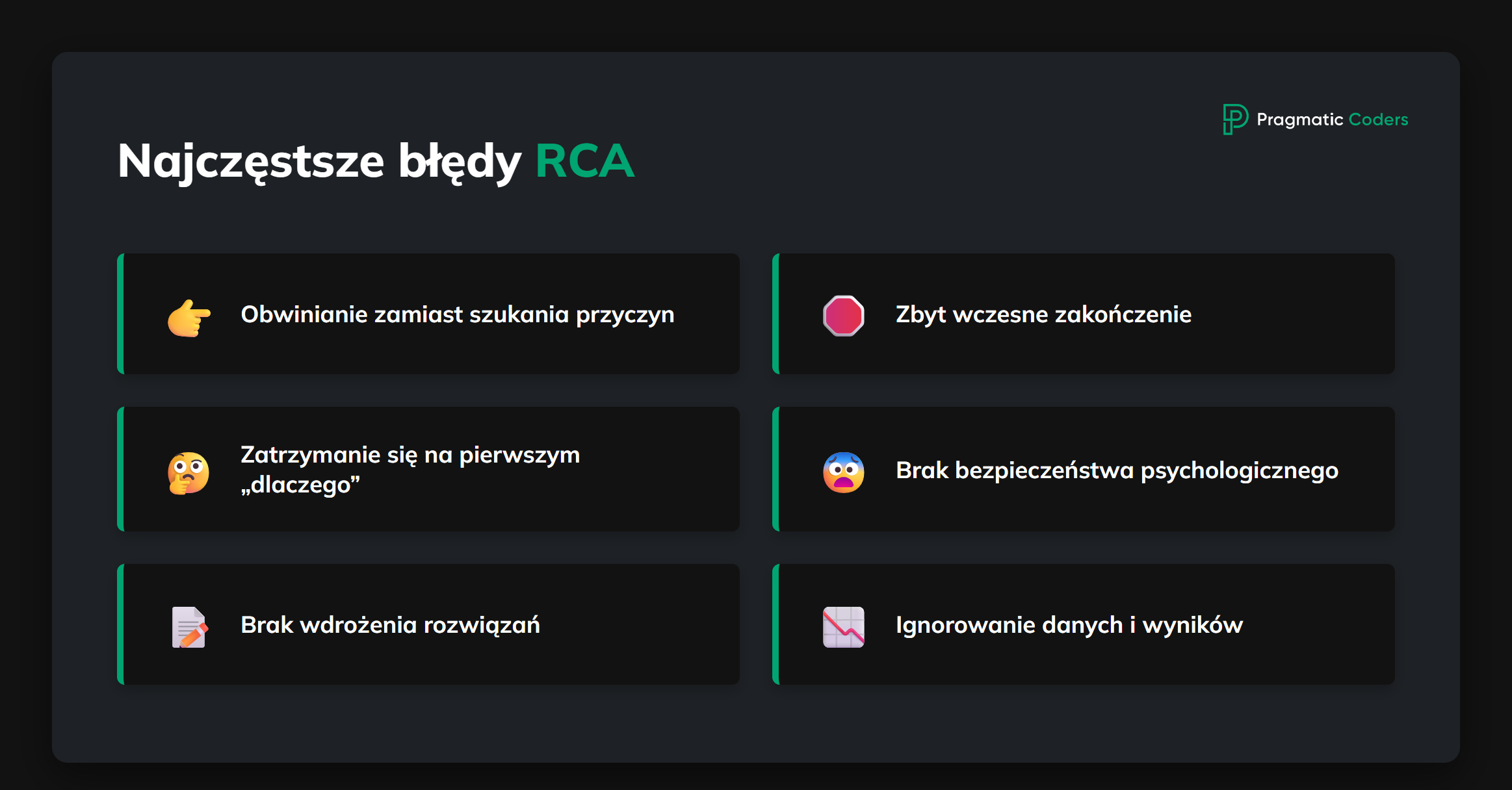
- Szukanie winnego zamiast przyczyny źródłowej. Zatrzymywanie się na etapie „Krzysiek i Adam zapomnieli”, bez pytania: „dlaczego można było o tym zapomnieć?”.
- Zatrzymanie się po pierwszym pytaniu „dlaczego”. Prawdziwa przyczyna leży zazwyczaj 3–5 poziomów głębiej (refinement, brak standardów, brak walidacji, dług).
- Brak bezpieczeństwa psychologicznego. Jeśli ludzie boją się przyznać do błędu, RCA zamienia się w teatr.
- Brak wdrażania wniosków. Masz ładny dokument w Confluence, ale DoR/DoD, listy kontrolne i tablice pozostają bez zmian.
- Ignorowanie danych historycznych. Skupienie się tylko na tym, że „naprawiliśmy błąd”, bez uwzględnienia istniejących rekordów i użytkowników.
- Brak mierzenia rezultatów. Bez metryk trudno stwierdzić, czy analizy RCA rzeczywiście coś poprawiają.
Przykładowy szablon spotkania RCA (do ponownego wykorzystania)
Możesz wykorzystać ten schemat jako szkielet swojego spotkania RCA:
- Cel spotkania (5 min):
- Jaki incydent analizujemy?
- Co chcemy zrozumieć / ustalić / zmienić?
- Rekonstrukcja zdarzeń (10–15 min):
- Co dokładnie się stało, krok po kroku?
- Co widział użytkownik / klient?
- Co mówią logi?
- Trzy ścieżki (20–40 min):
- Dlaczego błąd wystąpił? (refinement, wymagania, decyzje)
- Jak zareagowaliśmy? (komunikaty, wsparcie, komunikacja wewnętrzna)
- Jak go naprawiliśmy? (czy naprawa jest kompletna, co z danymi historycznymi?)
- Wnioski procesowe (15–20 min):
- Co dodajemy/zmieniamy w DoR?
- Co dodajemy/zmieniamy w DoD?
- Jakie standardy / dobre praktyki wprowadzamy?
- Plan wdrożenia (10 min):
- Kto odpowiada za dane działanie?
- Skąd będziemy wiedzieć, że zmiana działa (metryki)?
- Kiedy wrócimy do tematu, by sprawdzić efekty?
FAQ – Najczęstsze pytania o RCA
Czy RCA to samo co post-mortem?
Nie. Post-mortem to szersza refleksja nad incydentem lub projektem (co poszło dobrze, co źle, jakie mamy nauczki). RCA skupia się konkretnie na przyczynach źródłowych i zmianach w procesie, aby zapobiec powtórkom.
Czy potrzebujemy RCA po każdym błędzie?
Nie. RCA ma sens głównie po:
- krytycznych incydentach,
- powtarzających się błędach,
- zdarzeniach o dużym wpływie biznesowym (utrata klienta, awaria w specyficznym czasie, długi przestój).
Przy małych błędach wystarczy mini-retro.
Jak długo powinno trwać spotkanie RCA?
Zazwyczaj od 30 do 90 minut. Kluczem jest:
- dobre przygotowanie danych wejściowych,
- konkretna rozmowa,
- wypracowanie 2–5 zmian procesowych do wdrożenia.
Kto powinien uczestniczyć w RCA?
- programiści / inżynierowie znający dany obszar,
- Product Owner / analityk (perspektywa biznesowa),
- czasami dział wsparcia / sprzedaży (głos użytkownika),
- moderator (pilnujący struktury i bezpieczeństwa).
Czy można przeprowadzić RCA zdalnie?
Tak. Narzędzia, które świetnie się sprawdzają to:
- Miro / Mural (mapy wizualne),
- Google Docs / Confluence (notatki na żywo),
- Zoom / Teams itp. z włączonymi kamerami (buduje zaufanie).
Jak zacząć wprowadzać RCA w organizacji?
Zacznij od jednego konkretnego incydentu. Przeprowadź analizę zgodnie z zasadami, wypracuj 2–3 realne usprawnienia procesu, pokaż je biznesowi w liczbach (koszty, poprawki) i jako konkretne korzyści.
Podsumowanie: RCA jako nawyk – „dziś lepiej niż wczoraj”
RCA to nie jest jednorazowe „narzędzie kryzysowe”. To element kultury, który polega na:
- pytaniu „dlaczego?” zamiast „kto zawinił?”,
- myśleniu systemami i procesami zamiast jednostkami,
- łączeniu incydentów technicznych z realnymi kosztami biznesowymi,
- mierzeniu postępów i cieszeniu się z tego, że dziś jest o drobinę lepiej niż wczoraj.
Warto zapamiętać te słowa:
„Pomaga mi mówienie sobie: spraw, by świat każdego dnia był trochę lepszy – mój świat, mój produkt. Czasami frustruje mnie to, że chcę być pięć kroków do przodu, a my wciąż gasimy pożar. Wtedy świetnie jest mieć metryki i zobaczyć: hej, jest lepiej niż było wczoraj. Może powoli, może nieidealnie, ale lepiej niż wczoraj”.
Dla nas w Pragmatic Coders RCA to nie tylko metoda – to część naszego stylu pracy. Bez względu na to, czy budujemy skalowalne aplikacje bankowe dla Atom Bank, czy modernizujemy oparte na AI platformy medyczne, takie jak WithHealth, zawsze analizujemy dlaczego coś się dzieło, a nie tylko co się stało. W ten sposób nieustannie ulepszamy produkty i procesy, krok po kroku. Jeśli szukasz partnera technologicznego, który pracuje w taki sposób, skontaktuj się z nami.





