Czym jest bus factor?
Bus factor to jedno z najważniejszych pojęć związanych z długiem technicznym, systemami legacy i ogólną kondycją projektu. Im jest niższy, tym gorzej. Dlatego w tym artykule wyjaśniamy, czym jest, dlaczego spada i jak go podnieść.
Dowiedz się więcej, jak zdiagnozować swój projekt. Koniecznie pobierz nasz e-book „Czy Twój projekt płonie? Autodiagnoza”:
![Czy twój projekt płonie [EBOOK]](https://www.pragmaticcoders.pl/wp-content/uploads/sites/2/2026/02/Czy-twoj-projekt-plonie-EBOOK.jpg)
Czym jest bus factor?
Bus factor (znany też jako truck factor) to wskaźnik ryzyka dla zespołu/projektu: oznacza minimalną liczbę osób, które musiałyby nagle stać się niedostępne (np. odejść z pracy, zachorować, zostać przeniesione do innego projektu — obrazowo: „wpaść pod autobus”), żeby projektu nie dało się dalej utrzymywać albo dowieźć.
Bus factor = 1 → bardzo duże ryzyko: jedna kluczowa osoba trzyma krytyczną wiedzę i/lub dostępy.
Im wyższy bus factor → tym większa odporność: wiedza, odpowiedzialność i dostępy są rozłożone na kilka osób.
Skąd się bierze bus factor?
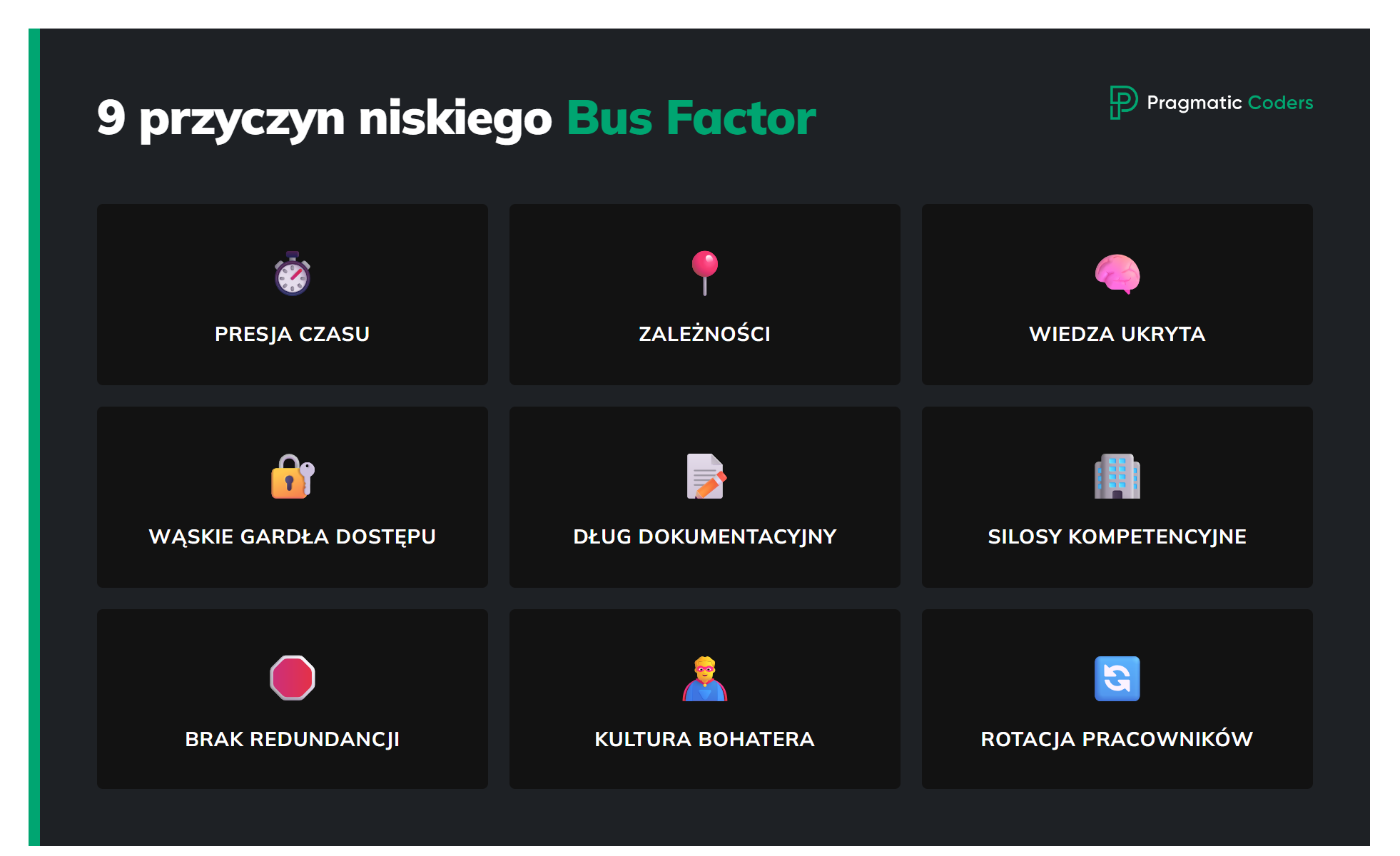
Bus factor bierze się stąd, że w projektach wiedza, dostępy i odpowiedzialność „same z siebie” lubią zbijać się w jedno miejsce — chyba że świadomie temu przeciwdziałasz. Gdy pojawia się presja czasu, najłatwiejsza droga to ta na skróty: „niech zrobi to osoba, która już to zna”. To działa szybko tu i teraz, ale utrwala specjalizację i sprawia, że jedna osoba staje się domyślnym wyborem do coraz większej liczby tematów.
Do tego dochodzi efekt pierwszego autora: ktoś, kto postawił dany system albo moduł, zna historię decyzji, kontekst i wszystkie obejścia, więc naturalnie przejmuje rolę opiekuna. Z czasem w jego głowie gromadzi się wiedza, której nie widać w kodzie ani w dokumentacji — mentalne mapy, „haczyki”, powody, dla których coś jest zrobione akurat tak, oraz intuicja w diagnozowaniu problemów. To jest wiedza ukryta, której nie da się łatwo przekazać w biegu.
Równolegle często powstają wąskie gardła w dostępie: klucze do produkcji, uprawnienia administracyjne, kontakty do vendorów czy prawa do wdrożeń zostają u jednej osoby „dla bezpieczeństwa” albo po prostu z rozpędu. Dokumentacja zwykle nie nadąża za tempem zmian, więc dług dokumentacyjny rośnie, a wejście w temat wymaga coraz większego kontekstu. Jeśli organizacja dodatkowo wzmacnia to strukturą ról — pojedynczym „ownerem”, silosami albo samotnym specjalistą od DevOps, danych czy CRM — ryzyko robi się systemowe.
Na koniec wchodzi czynnik ludzki: wiele firm nagradza „bohaterów”, którzy zawsze ratują sytuację, co niechcący zniechęca do dzielenia się wiedzą i delegowania. A gdy dochodzi rotacja ludzi między projektami, osoba, która zostaje najdłużej, staje się kotwicą wiedzy — i w praktyce jedynym punktem awarii. W efekcie bus factor nie jest wyjątkiem, tylko naturalnym skutkiem ubocznym optymalizacji na szybkość, jeśli nie budujesz redundancji celowo.
Jak sprawdzić czy bus factor w twoim produkcie jest niski?
Nie jest tak, że „masz albo nie masz” bus factor — on zawsze istnieje. Pytanie brzmi tylko: czy jest niebezpiecznie niski. I da się to sprawdzić całkiem praktycznie.
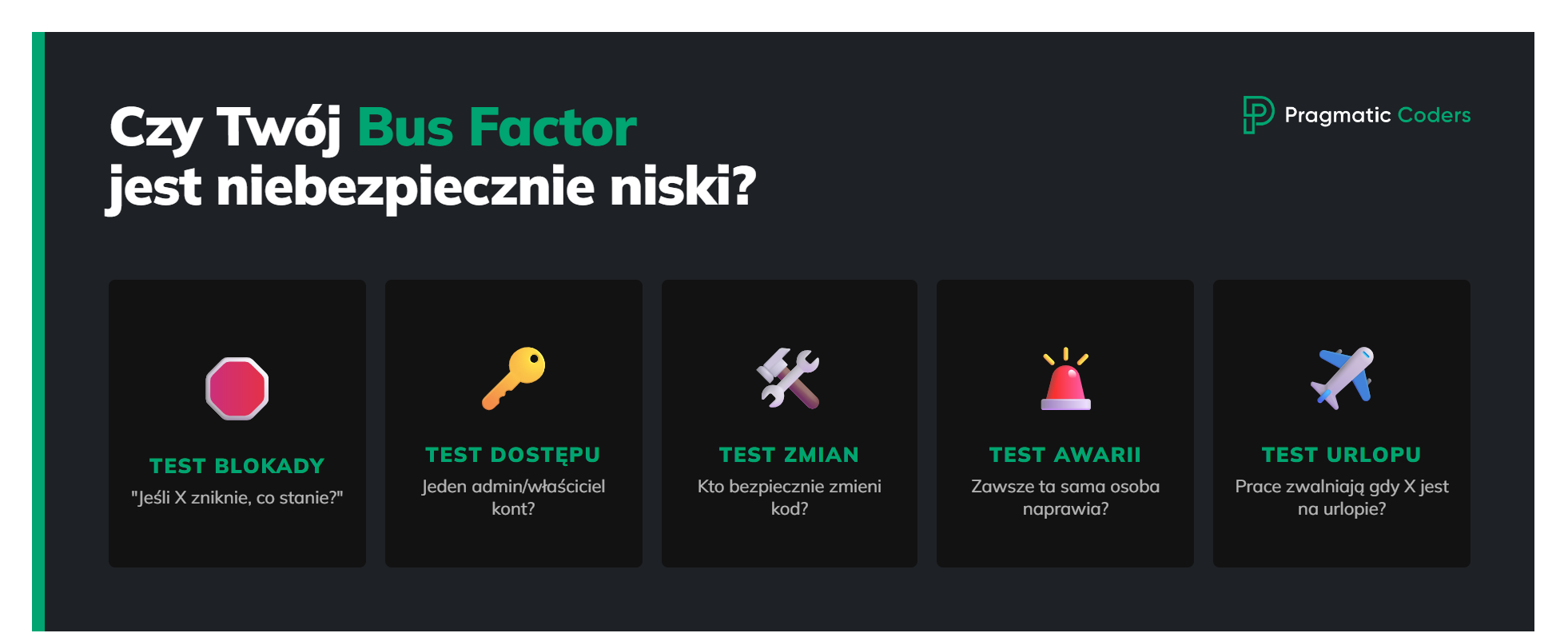
Zacznij od prostego pytania: „Jeśli X wypada na 2 tygodnie, co staje?” Jeśli potrafisz od razu wskazać konkretną osobę i rozpisać łańcuch zależności („bo tylko ona ma dostęp”, „bo tylko ona zna integrację”, „bo tylko ona robi release’y”), to ten obszar ma bus factor w okolicach 1.
Potem zrób test dostępu: kto może wdrożyć, zatwierdzić, wejść na produkcję, zarządzać CRM/reklamami, odnowić umowy z vendorami? Jeżeli odpowiedź brzmi „jedna osoba”, to dla tej zdolności bus factor też wynosi około 1 — niezależnie od tego, ile osób „teoretycznie” jest w zespole.
Kolejny krok to test zmiany: kto potrafi bezpiecznie modyfikować ten system bez pytania kogokolwiek o zgodę, kontekst albo „jak to działa”? Jeśli tylko jedna osoba czuje się na tyle pewnie, żeby zrobić zmianę end-to-end, to bus factor jest niski, bo reszta jest w praktyce zablokowana.
Bardzo trzeźwiący bywa test incydentu: spójrz na ostatnie 3 awarie albo eskalacje i sprawdź, kto je finalnie dowiózł. Jeśli to ta sama osoba, masz koncentrację wiedzy i odpowiedzialności — i ryzyko, które rośnie z każdym kolejnym „ratowaniem sytuacji”.
Na koniec test urlopu: czy tempo realnie spada, gdy konkretne osoby są na wakacjach? Jeśli tak, to masz single point of failure — miejsca, gdzie bus factor jest za niski, żeby projekt był odporny.
Jak obliczyć bus factor?
Bus factor „liczysz”, tłumacząc definicję na coś, co da się policzyć:
Bus factor = minimalna liczba osób, które muszą wypaść, żeby projekt stanął.
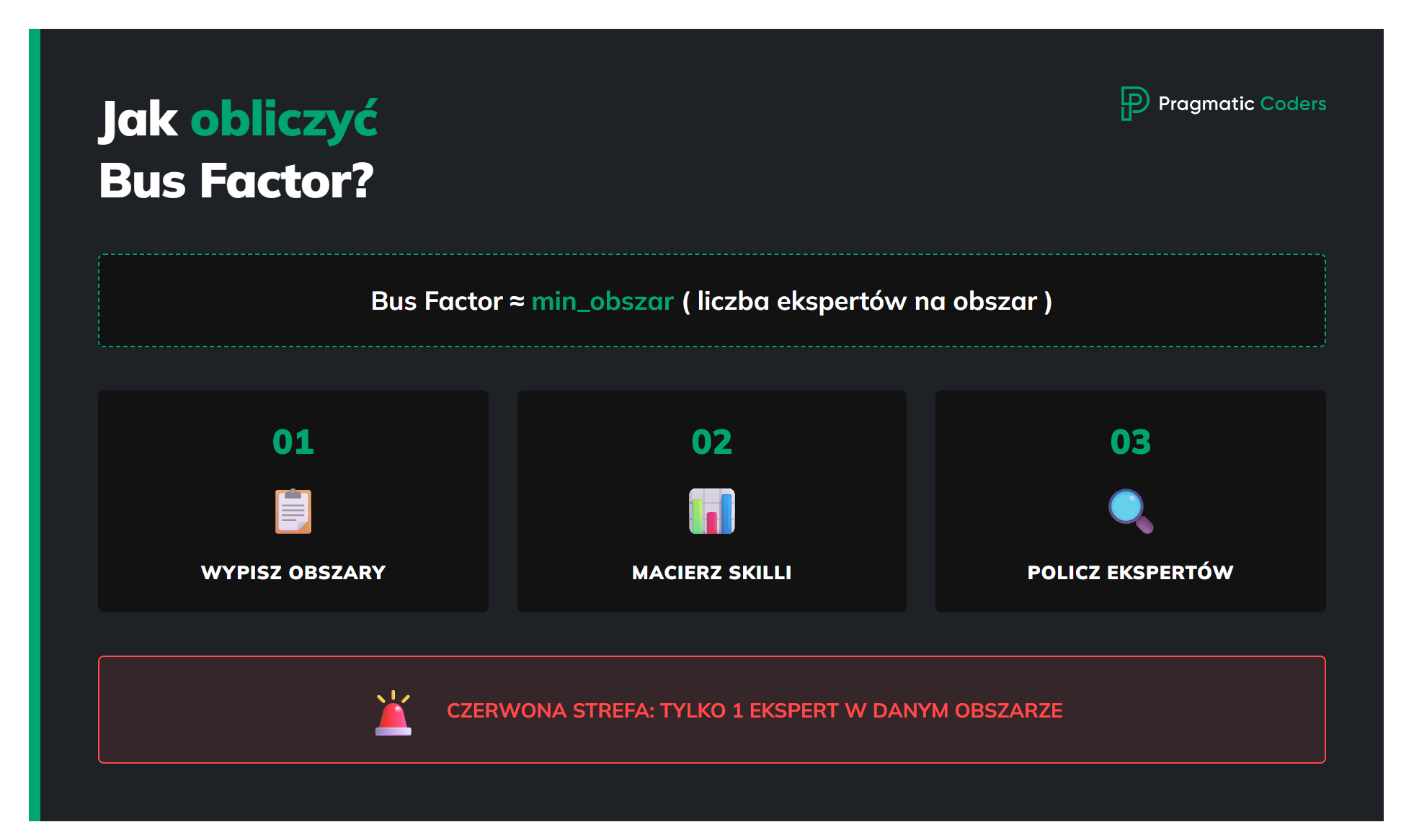
W praktyce najczyściej działa podejście operacyjne: potraktuj projekt jako zestaw kluczowych obszarów kompetencji/zdolności i policz, ile osób potrafi każdy z nich ogarnąć end-to-end.
Najpierw wypisz krytyczne obszary techniczne i biznesowe (np. wdrożenia/release, reakcja na incydenty, billing i rozliczenia, kluczowe integracje, raportowanie, wiedza o krytycznym kliencie, itp.). Potem zrób macierz kompetencji ze skalą 1–4 (1 = nie zna, 4 = ekspert).
Dla każdego obszaru policz coverage = liczba osób z oceną 3–4, czyli takich, które są w stanie dowieźć temat samodzielnie, bez prowadzenia za rękę. To dokładnie odpowiada testowi „red zone” z e-booka: red zone to sytuacja, w której w danym obszarze tylko jedna osoba ma poziom 3–4.
Operacyjnie bus factor projektu to po prostu najmniejsze pokrycie wśród obszarów krytycznych:
bus_factor ≈ min_area( liczba osób z poziomem 3–4 w obszarze )
Czyli jeśli wdrożenia mają 2 osoby „samodzielne”, raportowanie 3, ale kluczowa integracja tylko 1, to cały projekt ma bus factor w okolicach 1 — bo nadal istnieje pojedynczy punkt, który potrafi unieruchomić dowożenie.
Jak policzyć bus factor – przykład
Zespół (przykład) i skala ocen
Zespół:
- Ania (backend)
- Bartek (DevOps)
- Kasia (data)
- Tomek (frontend)
- Ewa (PM / ops)
Skala 1–4:
- 1 = brak praktycznej wiedzy
- 2 = pomoże z prowadzeniem / instrukcją
- 3 = zrobi samodzielnie
- 4 = ekspert / potrafi uczyć
Krok 1: Zdefiniuj „obszary” (capabilities)
Wybierz rzeczy, które jeśli nikt nie umie ich zrobić, projekt realnie staje.
Przykładowe obszary:
- Wdrożenie na produkcję i rollback
- Płatności i billing (Stripe)
- Kluczowe API (order service)
- Pipeline danych i raportowanie
- Release frontendu i feature flags
- Reakcja na incydenty / runbooki on-call
- Onboarding kluczowych klientów
Krok 2: Macierz umiejętności (skala 1–4)
(3–4 = „zrobi samodzielnie”)
| Obszar | Ania | Bartek | Kasia | Tomek | Ewa |
| 1) Deploy & rollback | 2 | 4 | 1 | 1 | 1 |
| 2) Payments & billing | 3 | 2 | 1 | 1 | 2 |
| 3) Core API | 4 | 2 | 1 | 1 | 1 |
| 4) Data pipeline | 1 | 1 | 4 | 1 | 2 |
| 5) Frontend release | 1 | 1 | 1 | 4 | 2 |
| 6) Incident response | 2 | 3 | 2 | 1 | 2 |
| 7) Customer onboarding | 2 | 1 | 2 | 1 | 3 |
Krok 3: Policz „coverage” na obszar (≥3)
Definicja: coverage(obszar) = liczba osób z oceną ≥ 3 (czyli dowiozą samodzielnie).
- Deploy → Bartek = 1
- Payments → Ania = 1
- Core API → Ania = 1
- Data pipeline → Kasia = 1
- Frontend release → Tomek = 1
- Incident response → Bartek = 1
- Onboarding → Ewa = 1
Krok 4: Wylicz bus factor
Bus factor projektu ≈ minimum coverage spośród obszarów krytycznych.
Tutaj najniższe coverage = 1, więc:
✅ Bus factor = 1
Czyli projekt ma dużo single pointów of failure — w każdym krytycznym obszarze jest tylko jedna osoba, która „dowiezie bez prowadzenia za rękę”.
Co zrobić z bus factorem?
Proponujemy konkretny, powtarzalny proces:
Najpierw policz bus factor tak, jak wyżej.
Potem:
1. Przypisz 1–2 osoby „backup” do każdej czerwonej strefy (red zone)
„Czerwona strefa” to każdy ważny obszar, w którym tylko jedna osoba potrafi ogarnąć temat dobrze (poziom 3–4 w macierzy).
Prosty przykład:
„Miesięczny raport dla klienta” → tylko Kasia wie, jak to zrobić → red zone.
Wybierz backupy: Ewa (Backup A) + Ania (Backup B).
Jak to zrobić w 20 minut:
- Zrób listę kluczowych obszarów (10–20).
- Przy każdym dopisz:
- Owner (rockstar) = osoba, która teraz zawsze to robi
- Backup A + Backup B = osoby, które nauczą się tego jako następne
- I tyle. Właśnie zamieniasz „wiedzę plemienną” w konkretny plan.
2. Mini playbooki (krótkie notatki „jak to działa”)
Następnie „rockstar” spisuje najważniejsze „jak to działa” w krótkim, praktycznym formacie.
Powinna to być maksymalnie jedna strona. Dobry mini playbook odpowiada na:
- Po co to jest?
- Gdzie wchodzę / co otwieram?
- Checklistę krok po kroku
- Typowe błędy + jak je naprawić
- Gdzie są hasła/dostępy (albo kto je nadaje)
Przykład: Kasia pisze „Miesięczny raport dla klienta – mini playbook”:
- link do arkusza / dashboardu
- „kliknij tu, wyeksportuj to, wklej tutaj”
- „przed wysyłką sprawdź 3 liczby”
- „jeśli liczby wyglądają źle: zrób 2 szybkie kontrole”
3. Rotuj odpowiedzialność
Chodzi o to, żeby zadanie wykonała osoba inna niż „rockstar” — w realnych warunkach, na prawdziwym przykładzie.
Jak zrobić rotację bez chaosu:
- Wybierz jedno nadchodzące, prawdziwe zadanie z czerwonej strefy.
- Przypisz je Backup A jako osobie, która ma je dowieźć („doer”).
- Rola rockstara jest tylko taka, żeby:
- być dostępny/a,
- zrobić szybki review wyniku,
- odpowiadać na pytania.
Przykład:
Następny miesięczny raport:
- Ewa przygotowuje i wysyła raport.
- Kasia patrzy i robi review, ale nie przejmuje zadania.
4. Sprawdzaj co 4–6 tygodni (czy jesteśmy mniej zależni?)
Regularnie aktualizuj obraz sytuacji: co 4–6 tygodni sprawdź, czy bus factor rośnie, czy dalej stoi na 1.
Jak to zrobić w ok. 30 minut:
- Wróć do listy czerwonych stref.
- Dla każdego obszaru zapytaj: „Czy jest już przynajmniej jeden backup, który umie dowieźć to end-to-end?”
- Jeśli tak → czerwona strefa jest „zamknięta” (albo przynajmniej wyraźnie poprawiona).
- Jeśli nie → zaplanuj kolejną rotację i zaktualizuj mini playbook.
Prosty wynik:
- Czerwone strefy łącznie: 8
- Czerwone strefy z backupem, który umie to zrobić: 3
- Cel na przyszły miesiąc: 5
Podsumowanie
Im wyższy bus factor, tym lepiej dla Twojego projektu. Mamy nadzieję, że ten artykuł pomoże Ci go rozpoznać i utrzymywać na bezpiecznym, wysokim poziomie.
Co dalej?
Jeśli chcesz jeszcze dokładniej zdiagnozować kondycję projektu, zajrzyj do e-booka o autodiagnozie projektu.
A jeśli nadal potrzebujesz wsparcia, odezwij się do nas i poproś o audyt projektu — chętnie pomożemy.
FAQ Bus factor
Co to jest bus factor równy 1?
Bus factor = 1 oznacza, że jest dokładnie jedna osoba, której nieobecność zatrzyma projekt (albo jego krytyczną część) — bo bez niej nie da się tego utrzymać ani dowieźć. W praktyce zwykle wygląda to tak: jedna osoba potrafi bezpiecznie robić deploy/release, jedna rozumie kluczową integrację, jedna „zawsze ratuje produkcję”, albo jedna trzyma niezbędne dostępy, loginy czy relacje z vendorami.
Jak policzyć bus factor?
Najprościej potraktować projekt jako zestaw krytycznych obszarów (capabilities) i zmierzyć „pokrycie” dla każdego z nich:
1) Wypisz obszary, które zablokowałyby dowiezienie projektu, gdyby nikt nie umiał ich ogarnąć (np. deploy/rollback, incydenty, kluczowe integracje, billing, raportowanie).
2) Zbuduj macierz umiejętności (np. skala 1–4, gdzie 3–4 = zrobi samodzielnie).
3) Dla każdego obszaru policz: coverage(obszar) = liczba osób z oceną 3–4.
4) Bus factor ≈ min_obszar(coverage(obszar)).
Jeśli w jakimkolwiek krytycznym obszarze coverage = 1, to realnie bus factor projektu wynosi 1.
Jaka wartość bus factor jest dobra?
To zależy od kontekstu, ale typowe progi interpretacji wyglądają tak:
– 1: krytyczne ryzyko (single point of failure)
– 2: krucho (jest jakaś redundancja, ale łatwo projekt zablokować)
– 3–4: zdrowo dla wielu małych i średnich zespołów (praca idzie dalej mimo jednej nieobecności)
– 5+: bardzo duża odporność (częściej w większych, dobrze udokumentowanych organizacjach)
Częsty, sensowny cel: co najmniej 2 osoby potrafią dowieźć każdy krytyczny obszar end-to-end, a 3 osoby w tych najbardziej biznesowo krytycznych (deploy, incydenty, płatności, kluczowa logika domenowa).
Co oznacza bus factor w software developmencie?
W wytwarzaniu oprogramowania bus factor mierzy, jak bardzo skupiona jest krytyczna wiedza i dostępy związane z: decyzjami architektonicznymi („dlaczego tak”), procesem deploy/release, dostępem do produkcji i reagowaniem na incydenty, kluczowymi modułami/ścieżkami w kodzie, infrastrukturą/DevOps i zależnościami od vendorów, pipeline’ami danych i raportowaniem oraz workflowami specyficznymi dla klientów. Niski bus factor zwiększa opóźnienia w dowożeniu, wydłuża czas trwania awarii, utrudnia onboarding i dokłada długu technicznego, bo zmiany przechodzą przez wąską grupę „strażników kontekstu”.
Dlaczego bus factor bywa niższy, niż zespołom się wydaje?
Bo zespoły często liczą osoby, które „mogą pomóc”, a nie te, które potrafią dowieźć temat samodzielnie pod presją czasu. Właściwy test brzmi: „kto potrafi zrobić to end-to-end bez potrzeby dopytywania eksperta?” Jeśli odpowiedź to jedna osoba — bus factor dla tego obszaru to w praktyce 1.
Jak najszybciej poprawić bus factor?
Trzy ruchy o największym zwrocie:
1) Przypisz Backup A + Backup B do każdej czerwonej strefy (obszary, gdzie tylko jedna osoba ma poziom 3–4).
2) Spisz mini playbooki (max 1 strona): po co to jest, gdzie wejść, checklista kroków, typowe błędy, jak zdobyć dostęp.
3) Rób prawdziwe rotacje: backup wykonuje zadanie („ręce na klawiaturze należą do backupu”), a ekspert tylko robi review i odpowiada na pytania.
Jak często wracać do pomiaru bus factor?
Dobrą częstotliwością jest co 4–6 tygodni. Niech to będzie lekkie (ok. 30 minut): wróć do czerwonych stref i potwierdź, czy przynajmniej jeden backup potrafi już dowieźć każdy obszar end-to-end.
Czy różne części tego samego projektu mogą mieć różny bus factor?
Tak. To bardzo częste: wyższe pokrycie w „widocznych” obszarach (np. frontend) i niższe w tych ostrzejszych, mniej lubianych (infrastruktura, billing, legacy integracje, pipeline’y danych). Operacyjnie liczy się najsłabsze ogniwo: najbardziej krytyczny obszar o najniższym coverage wyznacza efektywny bus factor projektu.



