Observability w biznesie: jak przestać dowiadywać się o awariach od klientów

Wyobraźmy sobie typową ścieżkę użytkownika bez observability.
Zespół wrzuca zmianę na produkcję o 16:20. Pierwszy użytkownik trafia na problem o 16:22. Po prostu wychodzi, idzie do konkurencji albo porzuca proces zakupowy. Część z tych, którzy zostali, próbuje to zgłosić. O 18:00 mamy ticket na supporcie, ale programistów nie ma już w pracy.
Dopiero dzień później ktoś na to patrzy i rusza proces poszukiwania przyczyny, a następnie naprawy. Głuche telefony długo zajmują, a userzy muszą chcieć zgłosić błąd, zamiast po prostu wyjść i pójść do konkurencji.
Observability z alertami powinno dać nam feedback na Slacka o 16:22. 2 minuty po wrzuceniu wadliwej wersji lub wystąpieniu błędu. Nie: 2 godziny po incydencie nowy ticket w kolejce do supportu.
Bez observability time to discover (czas do odkrycia błędu) liczymy w godzinach, a z observability – w minutach. O większości najczęstszych błędów powinniśmy dowiedzieć się w ciągu 10 minut od wdrożenia zmiany.
Dopóki nie wiemy, że jest problem, on rośnie, a my nawet nie zdajemy sobie sprawy, że trzeba nad nim pracować.
Observability vs. monitoring
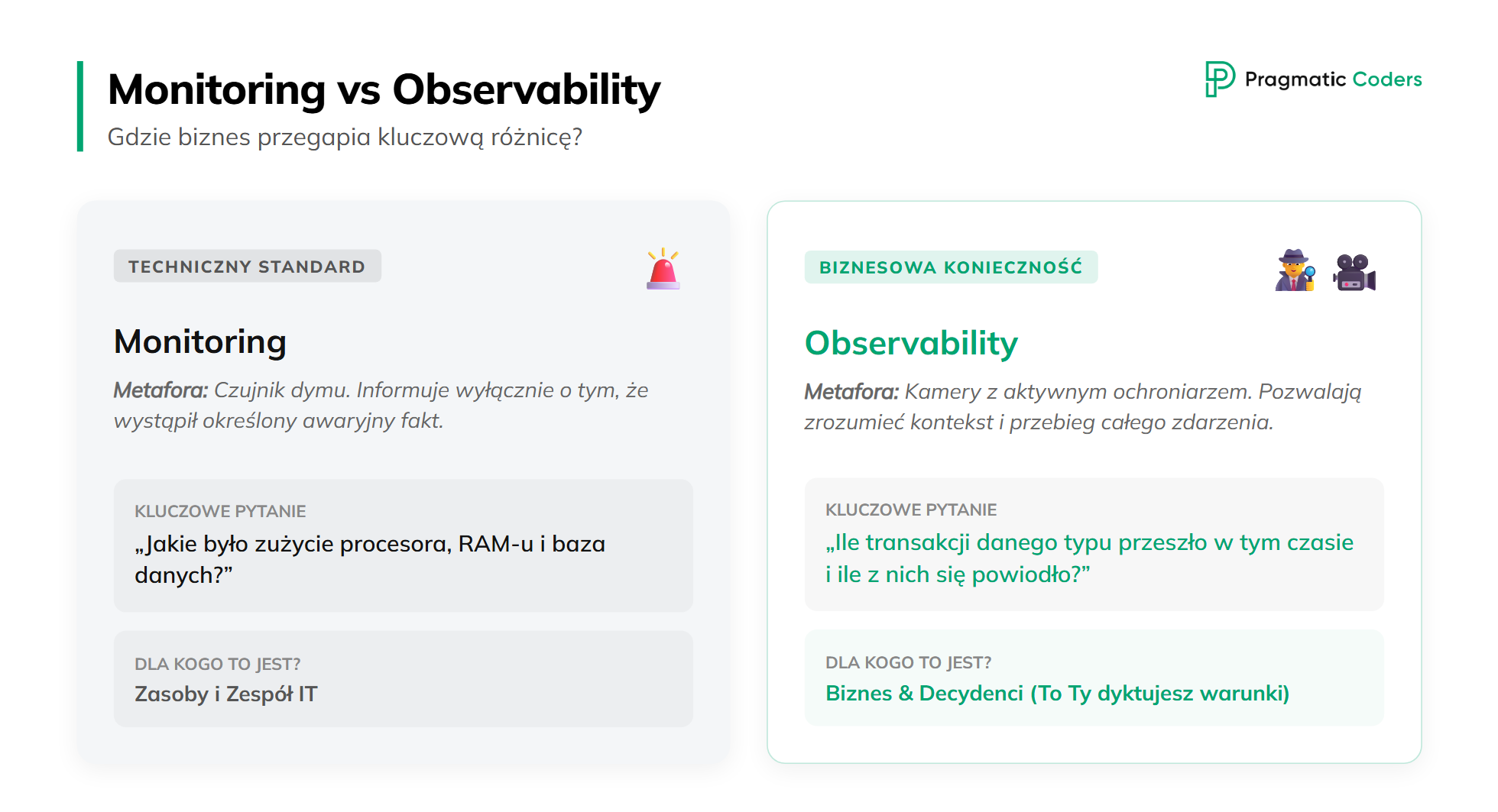
Monitoring, alerting i observability często są wrzucane do jednego worka. Deweloper mówi do biznesu: „pracowałem nad observability”. Biznes nic z tego nie rozumie i odpuszcza. Tak nie powinno być. Biznes powinien rozumieć observability i to biznes powinien dyktować, co obserwujemy.
Trochę inaczej jest z monitoringiem. Monitoring jest czymś technicznym. Sprawdzamy zużycie procesora, RAM, ilość zapytań do bazy.
Monitoring to czujnik dymu, observability to pokój, w którym siedzi ochroniarz i ogląda obraz z kamer.
Monitoring odpowiada na pytanie „jakie było zużycie procesora?”.
Observability odpowiada na pytanie „ile było transakcji danego typu w danym czasie i ile z nich się powiodło?”.
Pięć korzyści biznesowych. Czemu observability to nie jest zabawka dewelopera

Spada time to discover (TTD)
Mówię to już kolejny raz, ale to jest najważniejsze. Alerty na user impact. Dziesięć minut po deploymencie nowej wersji już wiemy, że użytkownik ma problem z dokończeniem zakupu. Time to discover spada drastycznie. A jak szybko wykryjemy, to szybko zaczynamy nad tym pracować lub szybko wycofujemy zmianę.
Spada time to repair (TTR)
Spada czas naprawy błędu dzięki temu, że wykryliśmy go automatycznie i mamy dużo szczegółów. Time to recovery też spada, bo wejście do zadania jest lepsze, bardziej jakościowe. Wiemy, co się stało, bo możemy prześledzić realne przypadki z produkcji. Nie pytamy „co się stało?”, tylko „jak to teraz naprawić?”.
Mniej poszkodowanych
Czyli mniej dotkniętych użytkowników. Pośrednio. Observability mówi nam, że userzy w danym segmencie mają problem. Na przykład w Warszawie. Albo na Androidzie. Albo z konkretnym planem subskrypcji. Możemy wycofać zmianę dla tych userów albo wyłączyć funkcjonalność feature flagą, jeżeli system jest na to gotowy. Observability umożliwia taką decyzję.
Lepsze decyzje co do incydentu
Może problem dotyka tylko jednego klienta i wystarczy do niego zadzwonić: „Słuchajcie, wiemy, że wam to nie działa, pracujemy nad tym, nie martwcie się”. Czy to nie jest lepsze niż to, że ten klient dzwoni do waszego CEO i mówi, że system nie działa?
Lepsze decyzje produktowe
Te same dane, które łapią incydenty, mówią też, czy nowa funkcjonalność jest faktycznie używana. W którym segmencie. Czy nie zepsuła czegoś innego. To zamyka pętlę między „wrzuciliśmy to” a „warto było to wrzucić”.
Case study: Orlikfy
Orlikfy to zbudowana przeze mnie aplikacja orlikowa, która w kompleksowy sposób obsługuje organizowanie, dołączanie i rozliczanie gier piłkarskich na orlikach. Mówiąc po ludzku: zamiast trzydziestu lokalnych grup na Facebooku w stylu „Orlik Gramy”, „Orlik Kraków”, „Piłka nożna Wrocław”, masz jedną aplikację, w której organizator wystawia gierkę na mapie, gracze sami ją znajdują i wpisują się jednym kliknięciem, a płatności są odnotowane w jednym miejscu.
Klasyczny dwustronny marketplace. Po jednej stronie organizator, który rezerwuje boisko. Po drugiej gracz, który chce w środę o 20:00 zagrać w piłkę. Z perspektywy biznesu są więc dwa krytyczne user flow:
- Tworzenie gry przez organizatora.
- Dołączanie do gry przez gracza.
Jeżeli któryś z tych flow przestaje działać, aplikacja w danym momencie nie dostarcza wartości użytkownikom.
Organizator nie wystawi gierki, więc gracze nie mają do czego dołączać. Albo gracze nie mogą się dopisać, więc organizator nie skompletuje składu i odwoła wydarzenie.
To są dokładnie te procesy, które observability musi obserwować w pierwszej kolejności. Reszta funkcjonalności (czat z graczami, oznaczanie zapłat, zapraszanie dawnych graczy do nowej gierki) jest w tej kolejności drugorzędna (nie znaczy że nie jest ważna).
Co konkretnie obserwujemy
Sprawdzamy stosunek prób do sukcesów. Ile osób w ogóle kliknęło „dołącz do gry”, a ilu osobom finalnie się to udało (z opłaconą rezerwacją). To samo z tworzeniem gry: ile prób, ile faktycznie wystawionych wydarzeń. Czasem się to nie udaje, bo na przykład gra w tym samym czasie jest już pełna albo płatność odrzucił bank. To okej. Mamy bazowe 3-5% błędów i to jest akceptowalne. Z różnych powodów zawsze jakieś błędy występują i tyle.
Próg, po którym coś jest nie tak
Decydująca jest zmiana, nie liczba bezwzględna. Jeżeli ten poziom rośnie do 30% błędów, coś jest nie tak. Observability powie nam: „Słuchaj, w tym ważnym procesie biznesowym coś się stało”, i wyśle wiadomość na Slacka do zespołu.
Cykliczność tygodniowa, czyli czemu twarde SLO mogę nie być najlepszym pomysłem
Jest jeszcze jedna sprawa. Nie jestem fanem ustawiania twardych celów typu „mamy mieć poniżej 1% błędów”, przynajmniej na początku. Bardziej jestem fanem odchylenia od historycznej normy. Pokażę dlaczego, na przykładzie Orlikfy.
W Orlikfy mamy bardzo wyraźną cykliczność tygodniową. Według naszych danych w poniedziałek odbywa się 3 razy więcej meczy niż w piątek!
W Orlikfy rozwiązaliśmy to tak: jeżeli analizujemy poniedziałek 16:20, bierzemy z trzech ostatnich poniedziałków dane z godziny 16:20. No ile było rozegranych gier.
Jeżeli odchylenie jest większe niż na przykład 30%, to może znaczyć że:
- (gdy wzrost) Gdzieś w internecie zaczęli o nas mówić mocniej niż zwykle?
- (gdy spadek) Zakończyliśmy kampanię marketingową 🙂 albo mamy błąd.
To jest rzecz, którą trzeba umieć w biznesie: czy dana zmiana w liczbach jest dobra, czy zła. Observability daje sygnał, na który należy spojrzeć.
Observability + AI = time to repair spada podwójnie

Nie da się napisać artykułu w 2026 roku i nie powiedzieć o AI. Ale tutaj akurat AI faktycznie ma piękny, wartościowy input.
Po pierwsze, dzięki observability i AI szybko dowiadujemy się o błędzie i automatycznie tworzymy ticket. W Jirze, na Slacku, gdziekolwiek. Proaktywnie. Observability tworzy zgłoszenie, do którego deweloper podchodzi już z gotową informacją. Wiemy co, gdzie, kogo, jakich userów, jaki segment. Mamy alert z pełnym kontekstem, segmentem userów, deployment trace (czyli po którym deploymencie się zaczęło) i możemy łatwo sprawdzić co się zmieniło w kodzie między tymi deploymentami.
Tutaj nie trzeba więcej kontekstu wyciągać z głowy: „o, jak nie działa rejestracja, to muszę sprawdzić X, Y i Z”. Nie. Dzięki observability to wychodzi z logów, mamy informacje, że error poleciał w danym miejscu, i to zarówno człowiek, jak i AI może przeanalizować. Sprzężenie observability z AI w idealnym świecie pozwoli proponować zmiany w kodzie automatycznie. Deweloper przychodzi po 30 minutach od pojawienia się błędu, ma gotowy pull request, opis co się stało i postmortem czemu do tego doszło. Może zaakceptować, wrzucić zmiany i zająć się tym, co zrobić, żeby uniknąć tego w przyszłości.
To nie tak, że w dniu pierwszym observability błędy same zaczną się wam naprawiać. Trzeba zrobić przestrzeń dla zespołu, żeby coś takiego wdrożyć. Samo to się nie zrobi, ale typowe proste błędy powinny być w takim setupie autonaprawialne.
Jak wdrożyć observability

Krok 1: wypiszcie 3 do 5 kluczowych procesów biznesowych
User journeys, endpointy, nieważne jak to nazwiecie. Te, na których zarabiacie, oraz te, których zepsucie boli najbardziej. Trzy do pięciu, nie więcej. Nie próbujcie obserwować wszystkiego naraz, bo skończycie z chaosem alertów, na który nikt nie patrzy.
Krok 2: zinstrumentujcie te procesy
Deweloper robi tak, żeby te procesy były faktycznie obserwowalne. Dodaje logi, ustawia alerty. Jeżeli log z błędem występuje częściej niż ustalony przez nas próg, leci wiadomość na Slacka. Te techniczne zawiłości zostawiamy zespołowi, ale biznes powinien znać efekt: każdy z wybranych procesów ma wskaźnik zdrowia, który widać w czasie rzeczywistym.
Warto żeby zespół zrobił to porządnie a nie na kolanie między taskami najmniej doświadczoną osobą w zespole.
Krok 3: ustalcie progi
Skąd wziąć ten próg „częściej niż ileś”? To jest challenge. Jeżeli nie ma w organizacji kultury observability, na początku jest to nieintuicyjne. Pytamy biznes: „Jaki procent błędnych transakcji akceptujemy?”. Odpowiedź to oczywiście: „Zero” 😉
I tu właśnie zamiast twardych SLO polecam podejście odchyleniowe: porównujemy bieżącą wartość do średniej z analogicznych okresów (te same dni tygodnia, te same godziny). Jak w przykładzie z Orlikfy trzy ostatnie poniedziałki o 16:20. Próg odchylenia ustalamy z biznesem i alertujemy, jak go przekroczymy. Sezonowość i kampanie marketingowe wbudowane w model.
Pułapka, w którą wpada większość firm
Wiele firm popełnia ten sam błąd: kupują Datadoga, czyli system do observability, i myślą, że jest załatwione. Otóż nie. Narzędzie to nie praktyka. Narzędzie to nie kultura inżynierska. Narzędzie to nie sensowny proces SDLC. To są trzy różne rzeczy i trzeba je zbudować osobno.
Druga pułapka to zamknięcie się na jednego dostawcę logów albo oprogramowania do observability. Wybierając rozwiązanie warto przemyśleć, czy łatwo da się je w razie czego zmienić. Bo nie zawsze jeden dostawca będzie pasował do każdego kontekstu, w jakim wasza firma się znajdzie za rok czy dwa, a i pricing dostawców lubi się zmienić.
Kultura observability przez Definition of Ready i Definition of Done

Samo wdrożenie narzędzia to za mało. Według mnie jedyny działający sposób, żeby observability stało się częścią kultury, to wpięcie go w standardowy proces. Żeby to zrobić, trzeba mieć dwie rzeczy: Definition of Ready i Definition of Done.
Definition of Ready mówi, kiedy zadanie jest gotowe, żeby zespół IT zaczął nad nim pracę. Definition of Done mówi, kiedy jest skończone. Observability nie wystarczy zaimplementować na etapie Definition of Done. Trzeba je dodać krok wcześniej, do Definition of Ready.
Przykład:
jeżeli dyskutujemy nową funkcjonalność z biznesem, to na tym etapie, jeszcze przed pisaniem kodu, zastanówmy się: jak zaobserwujemy zmianę w observability, czy userzy używają tego, czy nasz cel biznesowy jest osiągnięty. Na tak wczesnej fazie pozwoli nam to lepiej rozumieć, co właściwie robimy, bo będziemy wiedzieć, jak to zmierzymy. I będziemy też w stanie szybciej zareagować na błędy, bo już o nich rozmawialiśmy.
Oneliner do zapamiętania
Nie chodzi o to, żeby system nigdy nie padł. Chodzi o to, żeby dowiedzieć się o tym pierwszym, wiedzieć, kogo to dotyczy, i naprawić, zanim użytkownik napisze recenzję “jedna gwiazdka, nie działa, usuwam”.
Dzięki observability drastycznie zmniejszycie koszt incydentu na produkcji. Głównie przez redukcję time to discover, ale też time to repair, zwłaszcza z procesem sprzężonym z AI.
Nie wiesz jak wykorzystać observability to redukcji ryzyka i kosztów incydentów?, A może widzicie, że IT mówi „mamy Datadoga”, a alerty na realne incydenty biznesowe i tak nie docierają? Skontaktujcie się z nami po audyt. Pomożemy zmapować krytyczne user journey, zaprojektować metryki biznesowe i wdrożyć observability tak, żeby wpięło się w istniejący proces wytwórczy, a nie zostało zabawką dla deweloperów.





