Pięć czerwonych flag: diagnoza kluczowych problemów w rozwoju produktu IT

Masz nieodparte wrażenie – z twoim produktem i jego rozwojem jest coś nie tak. Nie potrafisz tego dokładnie nazwać – w końcu nie jesteś osobą techniczną – ale widzisz symptomy. Zespół techniczny zapewnia, że “pracują nad tym”, ale tempo jest coraz wolniejsze. Estymacje przestały mieć jakiekolwiek znaczenie. O problemach dowiadujesz się od klientów, a zespół jest regularnie czymś zaskakiwany przez system. Czujesz, że tracisz kontrolę, ale nie wiesz, jak to naprawić ani nawet jak o tym rozmawiać.
Projekty w tym stanie rzadko same się naprawiają. Bez interwencji czeka was albo kosztowna reanimacja, albo lata walki z systemem który was spowalnia – podczas gdy konkurencja was wyprzedza.
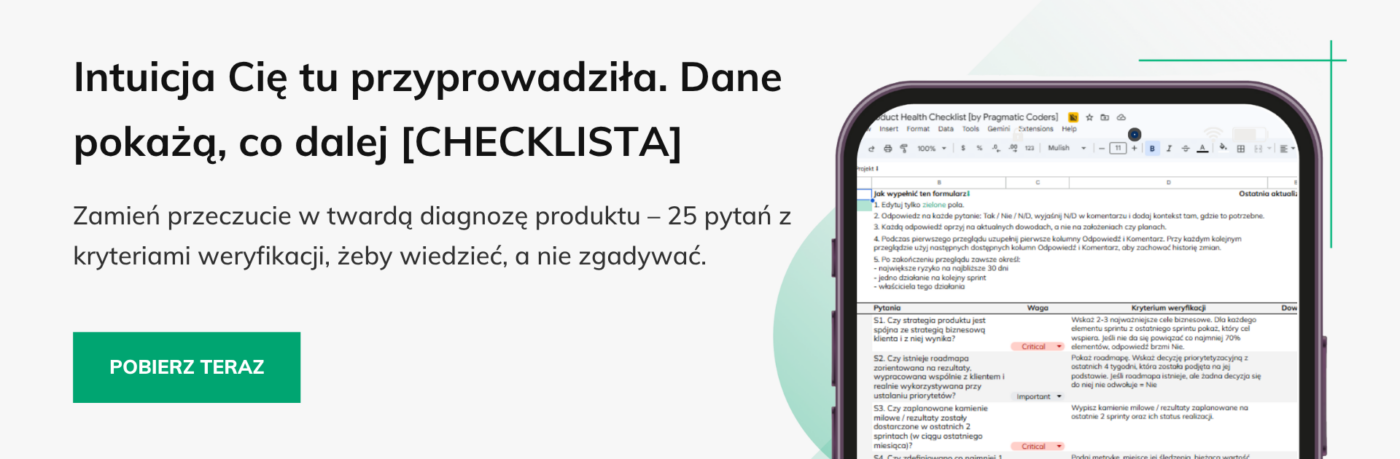
W tym artykule przedstawię ci pięć czerwonych flag, które regularnie znajdujemy w produktach IT tuż przed kryzysem – na bazie wieloletnich doświadczeń w wyciąganiu projektów z opresji. Po przeczytaniu tego artykułu będziesz wiedział, które z twoich codziennych obserwacji stanowią największe przeszkody w twoim produkcie oraz co naprawdę jest przyczyną chaosu.

RED FLAG #1: Rozwój produktu jest nieprzewidywalny i coraz wolniejszy
Czym się objawia:

- Estymacje nie są traktowane poważnie – “powiedzieli 2 tygodnie, czyli będzie miesiąc” – i zespół nie potrafi wyjaśnić dlaczego ani przewidzieć skali opóźnienia
- Roadmapa zmienia się co sprint, bo regularnie “wychodzą nieoczekiwane problemy”
- Coraz więcej czasu zajmuje zrobienie coraz mniejszych rzeczy
- Każda “prosta zmiana” okazuje się wymagać modyfikacji w wielu miejscach
- Biznes przestaje ufać obietnicom produktu, bo za często coś się opóźnia
- Wdrożenia odbywają się rzadko i są masywne – “zbieramy zmiany, żeby wrzucić wszystko naraz”
Co najczęściej znajdujemy jako przyczynę:
- Dług techniczny nagromadził się do poziomu, gdzie każda zmiana ciągnie lawinę innych zmian
- Brak testów automatycznych – każda zmiana wymaga ręcznego długotrwałego testowania
- Zespół gasi pożary zamiast budować – połowa czasu idzie na naprawy
- Ręczny proces wdrożeń sprawia, że release to kosztowne “wydarzenie” – więc robi się je rzadko, grupując zmiany
Widziałem to na własne oczy:
W jednym z projektów weszliśmy jako grupa do “zadań specjalnych” – zmiana kluczowej integracji, na którym opierała się główna funkcjonalność produktu. Na pierwszy rzut oka zadanie wydawało się proste: podmieniamy jedną integrację na drugą, obsłużymy różnice i gotowe.
Rzeczywistość okazała się brutalna. System nie miał testów automatycznych, a architektura sprawiała, że każda zmiana ciągnęła za sobą modyfikacje w dziesiątkach miejsc. Próba realizacji “na siłę” była skazana na porażkę.
Zdecydowaliśmy się na pozornie paradoksalne posunięcie: zanim rozpoczęliśmy właściwą pracę nad zmianą dostawcy, spędziliśmy pierwsze tygodnie na napisaniu testów i naprawie architektury. To było wyzwanie – system działał asynchronicznie i był mocno zintegrowany z zewnętrznymi serwisami, więc każda zmiana w działającym kodzie musiała być wprowadzana ostrożnie. Legacy code bez testów, słaba architektura – typowe problemy systemów, które rosły bez fundamentów. Dopiero wtedy przystąpiliśmy do właściwego zadania.
Rezultat? Samo przepięcie dostawcy – gdy mieliśmy już testy i poprawioną architekturę – zajęło mniej czasu niż pierwotnie planowane prace bez tego fundamentu. Nie oznacza to, że było łatwo – napisanie testów do legacy code to zawsze walka z niespodziankami, a klient musiał zaakceptować że przez pierwsze tygodnie nie ma namacalnego progresu w postaci widocznych zmian w produkcie. Ale projekt zakończył się sukcesem, a klient przyznał później, że spodziewał się trzy krotnie dłużej realizacji, nikt nie zakładał napisania testów i zmian architektury. Inwestycja w fundamenty okazała się kluczowa.
RED FLAG #2: Zespół techniczny nie komunikuje ryzyk, zanim nie staną się problemami

Czym się objawia:
- Słyszysz o problemie dopiero wtedy, gdy już jest za późno na zmianę kursu – “ehh, no wiedzieliśmy, że to może się zdarzyć…”
- Zespół ma tendencję do mówienia “zrobimy to, bez problemu”, nawet gdy wszyscy w środku czują, że będzie problem
- Ryzyko pojawia się w rozmowie dopiero jako “bloker” lub “nieprzewidziane problemy”, nigdy jako wcześniejsze ostrzeżenie
- Programiści mówią między sobą o potencjalnych problemach, ale nie komunikują ich na zewnątrz zespołu
- Zespół czeka, aż ktoś zapyta o ryzyka, zamiast proaktywnie je zgłaszać
Co najczęściej znajdujemy jako przyczynę:
- Zespół techniczny nie rozumie, że identyfikacja i sygnalizowanie ryzyk to część ich obowiązków
- Brak formalnego procesu i dedykowanego czasu na rozmowy o ryzykach – nie ma momentu w sprincie czy planowaniu, kiedy zespół świadomie przegląda potencjalne zagrożenia
- Niewypracowany język i framework do rozmowy o ryzyku – zespół nie wie, jak mówić o prawdopodobieństwie, wpływie i mitygacji w sposób zrozumiały dla biznesu
- Brak nawyku myślenia “co może pójść nie tak” podczas planowania – skupienie tylko na happy path
- Kultura “nie przynoś problemów bez rozwiązań” może to potęgować – zespół boi się sygnalizować niepewność bez gotowej odpowiedzi
Widziałem to na własne oczy:
Przejęliśmy projekt, w którym ilość długu technicznego przerosła nasze najśmielsze oczekiwania. Ryzyka gromadziły się latami – prawie brak testów, problemy z architekturą, infrastrukturą, błędy w logice biznesowej. Najgorsze było to, że nikt tymi ryzykami nie zarządzał.
Zaczęliśmy od biegania od pożaru do pożaru, ale pożary nie kończyły się – wypalało to zespół. W pewnym momencie zmieniliśmy podejście: zebraliśmy listę problemów, wyłuskaliśmy krytyczne tematy i przedstawiliśmy klientowi 4 duże punkty z łączną estymacją 1.5 miesiąca pracy części zespołu. Rozmowa była trudna – pokazaliśmy skalę zaniedbań i musieliśmy przyznać, że dług techniczny jest zawsze trudny do estymacji. Na poprawianiu fundamentów można spędzać nieograniczoną ilość czasu, więc musieliśmy z klientem ustalić realny próg, do którego dochodzimy. Część rzeczy musieliśmy odłożyć, część zaakceptować jako ryzyko.
Co ważniejsze – wypracowaliśmy sposób współpracy, gdzie klient rozumiał już, że sygnalizowanie ryzyk to nie narzekanie, ale część zarządzania produktem. Jego rola to świadome decyzje: “naprawiamy to teraz” albo “akceptujemy ryzyko i idziemy dalej”.
Bo ignorowanie problemów i zbieranie długu technicznego to prosta droga do sytuacji, gdzie pewnego dnia na stole ląduje lista 15 krytycznych ryzyk wymagających miesięcy pracy. A wtedy rozmowa z biznesem nie jest już tylko trudna – ona często kończy współpracę. Klient, który nagle dowiaduje się o skali zaniedbań, ma pełne prawo poczuć się oszukany i po prostu zmienić dostawcę.
RED FLAG #3: Decyzje produktowe opierasz na intuicji, nie danych

Czym się objawia:
- Planowanie sprintu zaczyna się od “wydaje mi się, że klienci potrzebują…” zamiast “dane pokazują, że…”
- Dyskusje o priorytetach kończą się głosowaniem lub decyzją najgłośniejszej osoby na spotkaniu
- Nikt nie potrafi odpowiedzieć na pytanie “skąd wiemy, że to jest teraz najważniejsze?” bez uciekania w anegdoty
- Po wdrożeniu nowej funkcji zespół nie wie, czy odniosła sukces – bo nie było zdefiniowane, co to właściwie znaczy “sukces”
- Roadmapa przypomina wishlist bez jasnego kryterium “dlaczego to, a nie tamto”
- Zespół nie rozróżnia opinii jednego głośnego klienta od realnego problemu, który dotyka większości użytkowników
Co najczęściej znajdujemy jako przyczynę:
- Brak zdefiniowanych metryk produktowych powiązanych z celami biznesowymi
- Nikt nie śledzi realnego użycia produktu – nie ma analytics, nie ma product telemetry, nie ma customer feedback loop
- Dane są zbierane, ale nikt ich nie analizuje, bo “nie ma czasu” lub “nie wiemy, jak je interpretować”
- Kultura organizacji nagradza szybkie działanie – decyzje są podejmowane zanim ktokolwiek sprawdzi dane, nawet jeśli są dostępne
- Hipotezy produktowe nie są traktowane jak hipotezy – tylko jak pewniki, które trzeba zbudować
- Brak nawyku zadawania pytań “co się stanie, jeśli tego nie zrobimy?” i “jak zmierzymy, czy to zadziałało?”
Widziałem to na własne oczy:
Klient bardzo naciskał na pewną funkcjonalność. Nam wydawało się, że to zbyt skomplikowane na tym etapie produktu. Klient nie dawał jednak za wygraną. Byliśmy w impasie – zderzały się dwa przeczucia: klient miał przeczucie, że jest to potrzebne, my – że nie.
Zamiast walczyć opiniami, zrealizowaliśmy funkcjonalność w najprostszej możliwej postaci i zaczęliśmy mierzyć. Jak się okazało, przez miesiąc tylko 0,01% użytkowników z niej skorzystało. Liczby pozwoliły podjąć decyzję bez emocji – wycofaliśmy się z funkcjonalności, bo komplikowała system nie dając wartości w zamian.
Ale metryki to nie tylko ochrona przed złymi decyzjami – czasem pokazują szanse, których w ogóle byśmy nie zauważyli. W innym projekcie zbudowaliśmy funkcjonalność, po uruchomieniu okazało się, że poziom wykorzystania przekroczył nasze najśmielsze oczekiwania wielokrotnie. To dało nam jasny sygnał: użytkownicy tego potrzebują, warto w to inwestować więcej. Dane pokazały nam kierunek rozwoju produktu, którego intuicja by nie podpowiedziała.
Dane nie zastępują intuicji – ale weryfikują ją. I czasem ratują nas przed kosztownymi błędami, a czasem wskazują kierunek, którego byśmy nie dostrzegli.
RED FLAG #4: Zespół techniczny nie rozumie biznesu i nie współodpowiada za wynik
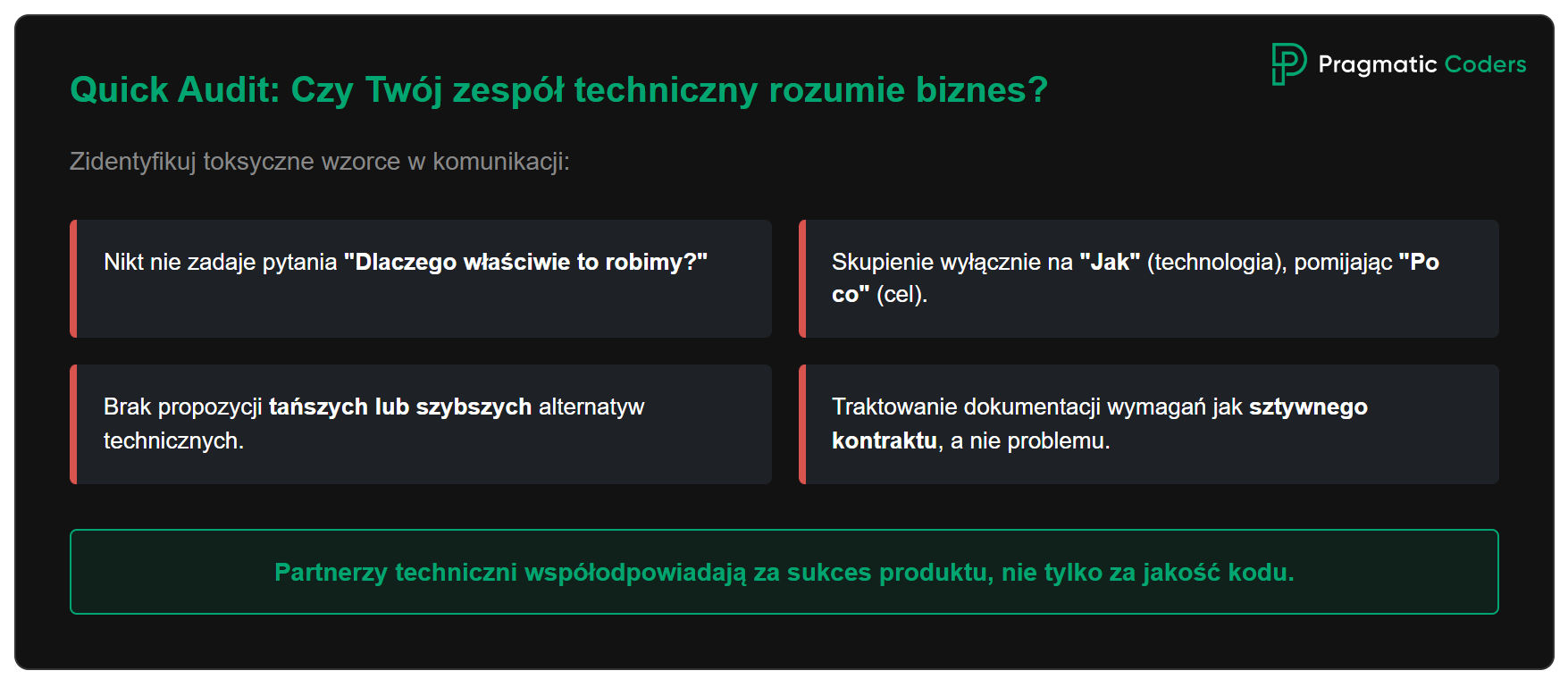
Czym się objawia:
- Programiści traktują user story jak listę wymagań do zrealizowania, nie jak problem do rozwiązania
- Rozmowy z zespołem technicznym przypominają tłumaczenie z obcego języka – dużo słów, mało zrozumienia
- Zespół proponuje rozwiązania bez zrozumienia kontekstu – “zrobimy to tak, bo to best practice”, nie “zrobimy to tak, bo w waszym przypadku najważniejsze jest X”
- Podczas planowania nikt z teamu nigdy nie pyta o biznesowe uzasadnienie
- Technologia staje się celem samym w sobie – refactoring, nowe frameworki, migracje, ale nikt nie potrafi wyjaśnić, jak to przełoży się na wynik biznesowy
Co najczęściej znajdujemy jako przyczynę:
- Zespół techniczny nie ma dostępu do klientów ani biznesowych metryk – albo organizacja ich odcina, albo sami się nie dopytują
- Brak wspólnego języka między biznesem a technologią – każda strona mówi swoim żargonem
- Product Owner lub PM robi się wąskim gardłem i filtrem, zamiast być facylitatorem rozmowy
- Zespół nigdy nie widzi efektu swojej pracy w postaci zadowolonych (lub niezadowolonych) użytkowników
Widziałem to na własne oczy:
Jeden z systemów który przejęliśmy działał – ale tylko w teorii. W praktyce obsługiwał wyłącznie scenariusze idealne. Jakiekolwiek odstępstwa od standardowej ścieżki i aplikacja sypała się w sposób kompletnie nieprzewidywalny dla użytkownika.
Kiedy dołączyliśmy do projektu po poprzednim dostawcy, szybko zobaczyliśmy dlaczego: zespół był szczelnie odizolowany od biznesu. Dostawał spisane wymagania, odhaczał je, a gdy pojawiały się wątpliwości – sam decydował jak coś ma działać. Bez konsultacji. Efekt? System formalnie “realizował wymagania”, ale kompletnie rozmijał się z tym, jak naprawdę wyglądała potrzeba biznesowa.
Jedna z pierwszych rzeczy którą zrobiliśmy, to skrócenie dystansu zespołu technicznego do biznesu. Zaczęliśmy bardzo bliską współpracę z zespołem operacyjnym i biznesem. W pewnym momencie spędziliśmy u klienta kilka dni, widywaliśmy się codziennie z zespołem operacyjnym, żeby zobaczyć od kuchni jak wygląda ich praca. Wątpliwości przestały być domysłami – szliśmy i pytaliśmy. Wdrożenia robiliśmy niemal codziennie, żeby informacja zwrotna docierała jak najwcześniej.
To podstawa: zespół techniczny, który nie rozumie po co coś robi, będzie dostarczał kod zgodny ze specyfikacją – ale niekoniecznie rozwiązujący problem.
RED FLAG #5: Zespół techniczny o problemach dowiaduje się od użytkowników
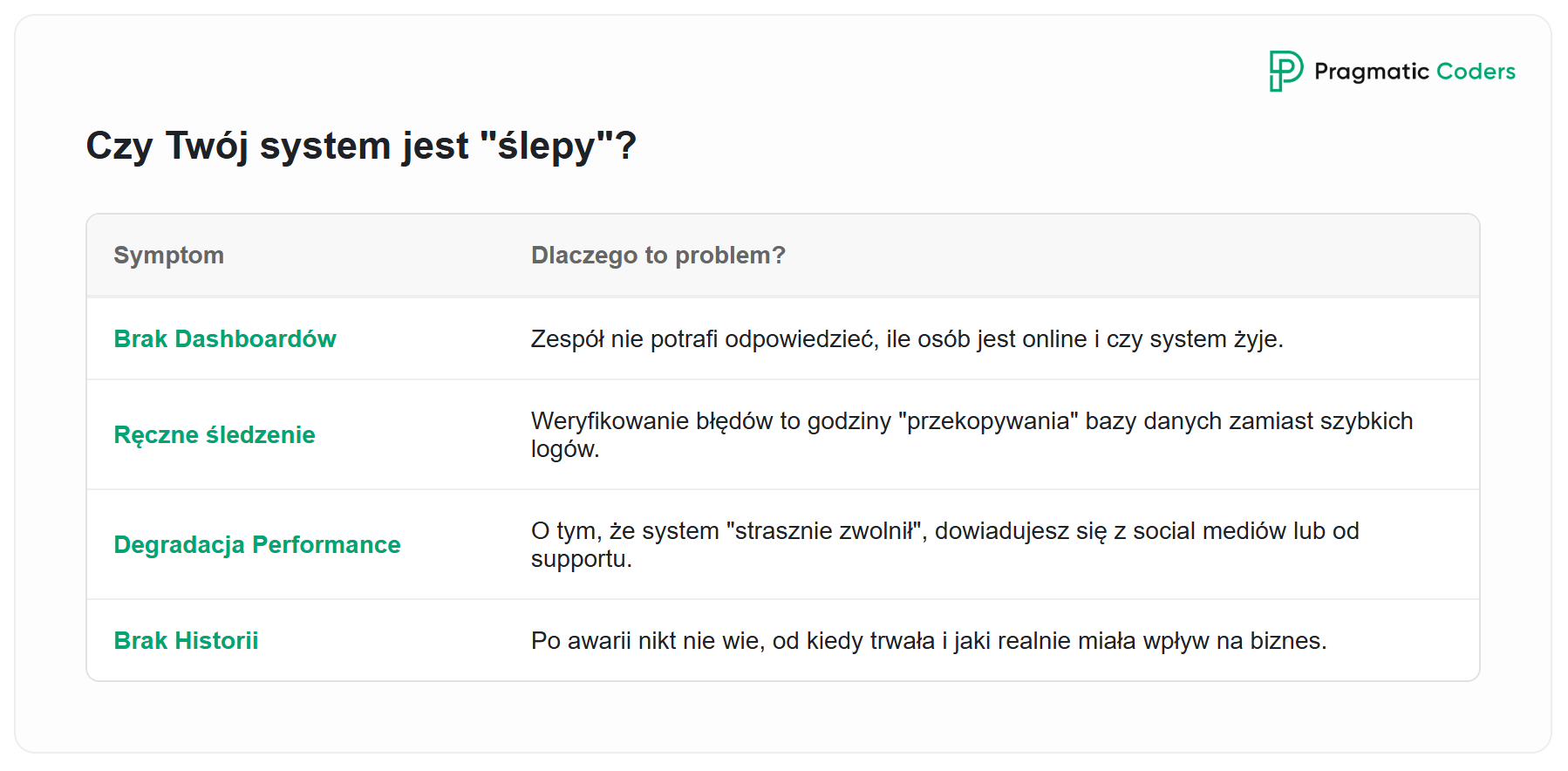
Czym się objawia:
- Informacja o tym, że coś nie działa, przychodzi bezpośrednio od użytkowników, nie z monitoringu
- Zespół nie wie, co się dzieje na produkcji w czasie rzeczywistym – weryfikowanie problemów to zgadywanie i sprawdzanie ręczne
- Degradacja wydajności jest zauważana przez użytkowników (“strasznie wolno działa”), nie przez zespół
- Brak odpowiedzi na podstawowe pytania: “czy system działa?”, “ile osób jest online?”, “czy są błędy?”
- Gdy problem w końcu się ujawni, zespół nie potrafi odpowiedzieć od kiedy trwa i jaki miał wpływ na użytkowników
Co najczęściej znajdujemy jako przyczynę:
- Brak narzędzi do obserwowania systemu – albo ich nie ma, albo są tak źle skonfigurowane
- Monitoring skupia się na infrastrukturze (czy serwery odpowiadają) zamiast na użytkownikach (czy klienci mogą wykonać swoją pracę)
- Logi są nieczytelne lub chaotyczne – podczas analizy problemu trzeba przeszukiwać setki linii bez kontekstu
- Brak alertów technicznych i biznesowych
- Błędy giną w logach i nikt ich nie analizuje systematycznie – zespół zaczyna szukać dopiero po zgłoszeniach użytkowników
- Zespół nie ma nawyku regularnego sprawdzania stanu produkcji
Widziałem to na własne oczy:
Znaczna większość systemów które przejmujemy nie ma zapewnionej obserwowalności. Logi są nieczytelne, postawione w przypadkowych miejscach, podczas analizy problemu niewiele mówią. Standardowa sytuacja po przejęciu wygląda tak: jakaś funkcjonalność zawodzi, a my odbijamy się od ściany – ciężko powiedzieć co poszło nie tak.
Dopiero dodanie logów w odpowiednich miejscach, ze zrozumieniem przebiegu funkcjonalności – pozwala przy ponownym błędzie powiedzieć coś więcej i finalnie naprawić problem tak, by nie pojawiał się ponownie. Dlatego zwykle jedna z pierwszych rzeczy które robimy, to praca nad obserwowalnością systemu, a następnie tworzenie alertów na konkretne wydarzenia – błędy wpadają prosto na komunikator jako powiadomienie, a my od razu wiemy że coś poszło nie tak.
W jednym z systemów niedługo po przejęciu, gdy nadal pracowaliśmy nad fundamentami, system kompletnie przestał odpowiadać. Wielogodzinna analiza wykazała, że źle zaprojektowana architektura sprawiła, że duży ruch zamroził cały system. Problem w tym, że nikt o tym nie wiedział, dopóki użytkownicy nie zaczęli dzwonić. Gdybyśmy na tamtym etapie mieli monitoring i alerty, zauważylibyśmy problem w kilka sekund i zareagowali zanim ktokolwiek zdążył to odczuć.
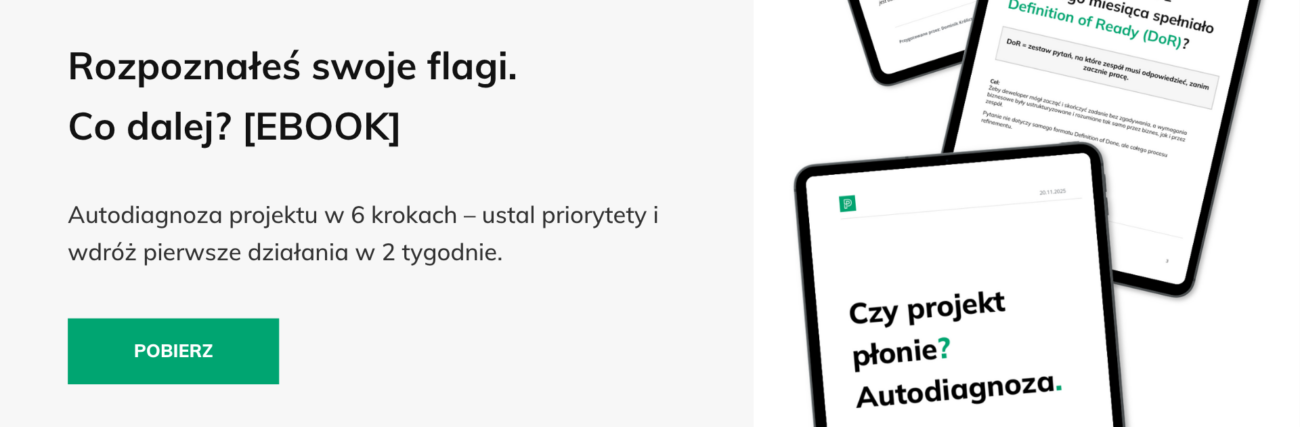
Podsumowanie
Teraz wiesz, które czerwone flagi mogą pojawiać się w twoim produkcie i co naprawdę za nimi stoi. Rozpoznanie problemu to pierwszy krok – ale samo zdawanie sobie sprawy nie rozwiąże sytuacji.
Każda z tych flag ma swoją przyczynę, często zagrzebaną głęboko w procesach, architekturze czy kulturze organizacyjnej. Jeśli rozpoznałeś jedną flagę – możesz zacząć targetować konkretny problem. Ale jeśli twoich czerwonych flag jest więcej niż jedna? Wtedy prawdopodobnie masz do czynienia z systemowym kryzysem, który wymaga głębszej interwencji.
Część zespołów potrafi to naprawić wewnętrznie – jeśli mają czas, wolę i mandat do wprowadzenia zmian. Inne potrzebują zewnętrznego spojrzenia i wsparcia, bo kryzys dotknął już tak wielu obszarów, że trudno określić priorytet działań.
W Pragmatic Coders specjalizujemy się w wyciąganiu projektów z trudnych sytuacji, gdzie większość problemów jest systemowa, nie punktowa – tam, gdzie potrzebna jest kompleksowa interwencja. Jeśli czujesz, że twój projekt wymaga tego rodzaju pomocy, skontaktuj się z nami.





