Dług techniczny a przychody: jak zmodernizować kluczowy system IT

Twój kluczowy system IT zarabia. Klienci płacą. Biznes od niego zależy.
Ale za każdym razem, gdy zespół naprawia jeden błąd, psuje się coś innego. Tempo wdrożeń spada. Niezawodność? Od dawna nie słyszałeś tego słowa. Utrzymanie zaczyna pochłaniać więcej uwagi inżynierów, niż ktokolwiek chciałby przyznać. To, co kiedyś wyglądało na zwykły problem techniczny, zaczyna dyktować tempo rozwoju firmy.
To typowy schemat w rosnących przedsiębiorstwach. Kod, który dzisiaj generuje przychody, może niepostrzeżenie stać się główną blokadą wzrostu w przyszłości. W praktyce to jedna z czterech najczęstszych ukrytych blokad produktywności zespołów IT – i ta, którą zwykle widać dopiero w wynikach finansowych.
Dobra wiadomość jest taka, że zazwyczaj nie musisz wybierać między tolerowaniem bałaganu a wyłączaniem systemu, żeby napisać go od nowa. W wielu przypadkach istnieje rozsądniejsza droga: ustabilizować to, co najważniejsze, zmniejszyć ryzyko i rozpocząć etapową modernizację, nie przerywając przy tym działania biznesu.
W skrócie
|
Dlaczego utrzymanie kluczowych systemów IT staje się tak trudne
Kiedy system oparty na złym kodzie zaczyna generować znaczące przychody, przestaje być wyłącznie problemem technicznym. Staje się krytyczną zależnością operacyjną.
Więcej klientów, więcej transakcji i więcej procesów zwiększa zasięg rażenia każdej zmiany. Błąd nie dotyka już tylko jednej funkcji. Może wpłynąć na płatności, onboarding, wsparcie klienta, raportowanie lub retencję. To zmienia sposób funkcjonowania firmy. Zarząd zaczyna unikać ryzyka, a zespoły łatają dziury zamiast wprowadzać ulepszenia. Poważniejsze naprawy są odkładane na później, bo biznesowi bardziej opłaca się kolejne tymczasowe obejście problemu niż gruntowne sprzątanie kodu.
Słabe fundamenty architektoniczne dodatkowo pogarszają sytuację. Problemy najszybciej nawarstwiają się w systemach, które od samego początku źle zaprojektowano, a potem utrzymywano przy życiu wyłącznie poprzez ciągłe łatanie. Kiedy zespół działa pod presją naprawienia kolejnego błędu, brakuje czasu na testy, dokumentacja jest nieaktualna, a kluczowa wiedza zostaje w głowach kilku osób. Strona biznesowa dodatkowo betonuje sytuację. Klienci polegają na systemie, przestoje dużo kosztują, a na całkowitą wymianę rzadko jest zgoda. Chyba że sprawy mają się już naprawdę źle.
W ten sposób kluczowy system zmienia się w pułapkę. Działa na tyle dobrze, by przetrwać, ale zbyt słabo, by bezpiecznie rosnąć.
Biznesowe koszty długu technicznego i słabego kodu
Niska jakość kodu nie tylko spowalnia programistów. Uderza też w stabilność aplikacji, terminowość wdrożeń, zaufanie klientów i elastyczność biznesową firmy.
Najbardziej odczuwalnym kosztem staje się codzienne utrzymanie aplikacji: ciągłe gaszenie pożarów, rosnąca liczba regresji, opóźnione wdrożenia i strach przed wypuszczaniem nowych wersji. Zespół marnuje czas na reagowanie na awarie, zamiast tworzyć nowe rozwiązania. W efekcie rozwój produktu hamuje. Zadania z roadmapy nie są realizowane, bo cały dostępny czas pochłania bieżąca praca operacyjna.
Koszty ukryte bywają jeszcze gorsze. Powracające problemy z niezawodnością frustrują klientów. Zespoły produktowe niechętnie deklarują terminy. Z kolei wprowadzanie do tak zaniedbanego kodu narzędzi AI może łatwo powiększyć szkody. Generują one zmiany szybciej, niż zespół jest w stanie je bezpiecznie zweryfikować. W efekcie jedna lokalna poprawka potrafi wywołać lawinę nieprzewidzianych skutków ubocznych.
Na tym etapie szkody przestają ograniczać się do kwestii technicznych. Przekładają się bezpośrednio na wolniejszą realizację celów, mniejszą pewność biznesową i zablokowanie potencjału do wzrostu firmy. Większość z tych kosztów da się zmierzyć, jeśli wiesz, gdzie szukać. Liczbowe ujęcie długu technicznego zamienia przeczucia w twardy argument biznesowy.
Kod zombie. Jak rozpoznać przestarzały system IT
Kod zombie to starsze rozwiązania, które technicznie nadal działają i obsługują klientów, ale funkcjonalnie są martwe: zbyt kruche i słabo rozumiane, by bezpiecznie je modyfikować. Nie każdy zaniedbany system od razu staje się kodem zombie. Część z nich dociera jednak do punktu, w którym rutynowe utrzymanie po prostu przestaje wystarczać.
Dług techniczny – sygnały ostrzegawcze
Zwróć uwagę na te sygnały:
- Tylko kilka osób potrafi bezpiecznie modyfikować kluczowe części systemu.
- Poprawki i wdrożenia (w tym zmiany generowane przez AI) regularnie powodują nowe błędy i nieprzewidziane skutki uboczne.
- Ciągłe gaszenie pożarów i reagowanie na awarie pochłaniają czas programistów, praktycznie blokując realizację zadań z roadmapy.
- Klienci coraz częściej zauważają problemy z niezawodnością i stabilnością.
Jeśli dotyczy Cię kilka z tych problemów naraz, to już nie jest zwykły bałagan w kodzie. Rutynowe sprzątanie tu nie pomoże – system wymaga przemyślanego planu naprawczego.
Szybki audyt IT: 6 pytań diagnozujących problem
Odpowiedz „tak” lub „nie” na te 6 pytań, aby szybko zdiagnozować sytuację w projekcie:
- Czy kluczowe zmiany zależą od jednej lub dwóch osób, które “po prostu wiedzą, jak to działa”?
- Czy ostatnie poprawki lub wdrożenia wywołały błędy w niepowiązanych obszarach?
- Czy zespół spędza więcej czasu na stabilizacji niż na dostarczaniu wartościowych usprawnień?
- Czy problemy z niezawodnością zaczynają uderzać w zaufanie klientów lub retencję?
- Czy zespół unika wprowadzania zmian w niektórych częściach systemu z obawy, że zepsuje coś innego?
- Czy kolejne próby uporządkowania kodu szybko stawały w martwym punkcie?
Jeśli odpowiedziałeś twierdząco na 0 do 2 pytań, system jest pod presją, ale wciąż można nad nim zapanować. Przy 3 do 4 odpowiedziach na „tak” ryzyko wyraźnie rośnie i wymaga zaplanowanej interwencji. Z kolei 5 lub 6 twierdzących odpowiedzi to znak, że system blokuje biznes. Zamiast kolejnych improwizacji, potrzebujesz ustrukturyzowanego planu ratunkowego dla swojego projektu IT.
Ratowanie projektów IT: jak zmodernizować system bez odcinania przychodów
Twoim celem na tym etapie nie powinno być natychmiastowe posprzątanie całego systemu. Zamiast tego skup się na zmniejszeniu ryzyka biznesowego i przywróceniu zespołowi możliwości bezpiecznego wprowadzania zmian.
Najpierw ustabilizuj krytyczne procesy biznesowe
Zacznij od tych części systemu, które są najmocniej powiązane z przychodami, zaufaniem klientów i ciągłością operacyjną.
Zmapuj kluczowe procesy. Zidentyfikuj te części systemu, których awarie generują największe straty finansowe. Wdróż monitoring w obszarach, w których obecnie działasz po omacku. Zabezpiecz proces wprowadzania najbardziej ryzykownych zmian i napisz precyzyjne testy dla obszarów, w których biznesu po prostu nie stać na żadne awarie. Jeśli wycofywanie błędnych wdrożeń (rollback) sprawia trudności, usprawnij ten mechanizm, zanim w ogóle spróbujesz przyspieszyć pracę zespołu.
To również moment, w którym musisz zaostrzyć kryteria Definition of Done. Jeśli zespół nadal będzie wypuszczał zmiany, które destabilizują system, realizacja planu ratunkowego zakończy się fiaskiem, zanim na dobre ruszy. Przerwanie tego błędnego koła jest na tym etapie znacznie ważniejsze niż jakakolwiek poprawa jakości samego kodu.
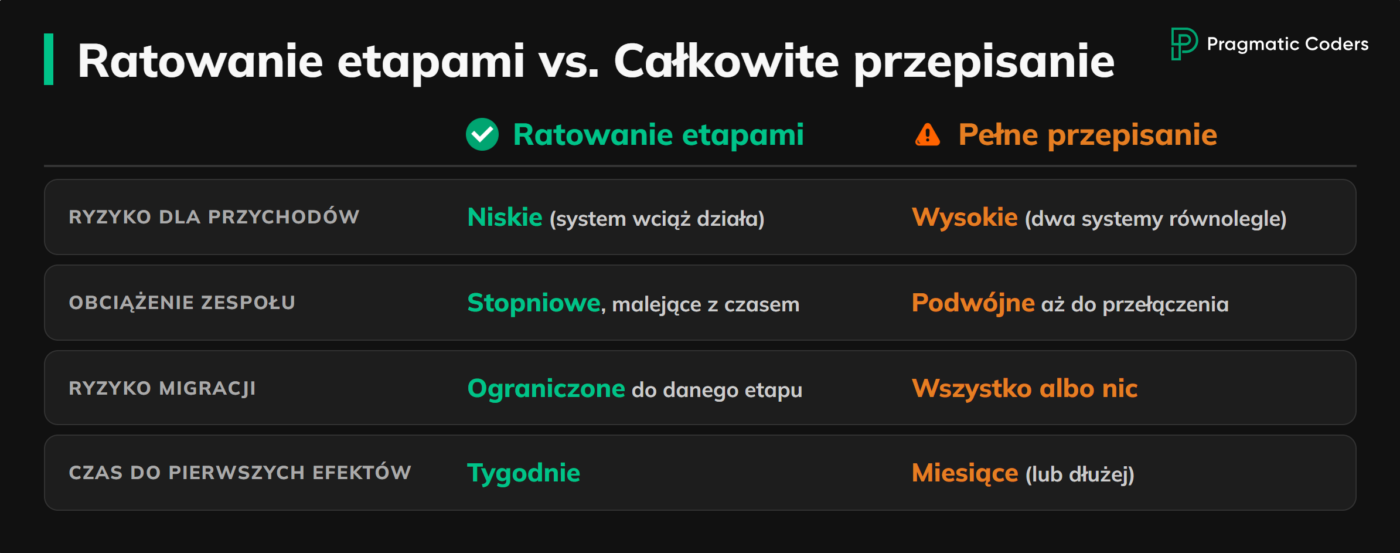
Postaw na etapową modernizację aplikacji
Gdy system odzyska stabilność, zacznij systematycznie uniezależniać się od jego najgorszych fragmentów, zamiast porywać się na przebudowę całości.
Większość projektów zyskuje na etapowej modernizacji znacznie bardziej niż na strategii pisania wszystkiego od zera. Nowe komponenty wdrażaj krok po kroku, jasno wyznaczając granice i izolując te fragmenty kodu, które sprawiają najwięcej problemów. Takie podejście drastycznie obniża ryzyko błędów przy przechodzeniu na nowe rozwiązania i pozwala firmie normalnie funkcjonować, podczas gdy zespół IT stopniowo odzyskuje moce przerobowe.
Pamiętaj, że w tym procesie nie chodzi o przepisywanie kodu po to, by architektura ładniej prezentowała się na schematach. Ta modernizacja ma wymiar czysto praktyczny – jej zadaniem jest zminimalizowanie zasięgu rażenia kolejnych usterek, odzyskanie pewności przy wdrożeniach i pozbycie się tych elementów systemu, które przynoszą firmie największe straty.
Dlaczego przepisanie systemu IT od zera to błąd
Napisanie systemu od zera kusi wizją czystej karty. W rzeczywistości oznacza to budowę drugiego projektu równolegle do starego, który przecież nadal musi działać i zarabiać.
Takie podejście podwaja obciążenie zespołu i winduje koszty znacznie szybciej, niż ktokolwiek zakładał. Stary kod wciąż wymaga poprawek i bieżącego utrzymania. Z kolei budowa nowego systemu pochłania czas tych samych inżynierów, którzy jako jedyni rozumieją działanie obecnego rozwiązania. W efekcie Twoi najlepsi ludzie muszą pracować na dwa fronty, na czym ostatecznie cierpią obie inicjatywy.
Drugim ogromnym problemem jest pułapka samej migracji, ponieważ zespoły nagminnie bagatelizują trudności związane z przenoszeniem logiki do nowej aplikacji. Kluczowe reguły biznesowe często ukrywają się w prowizorycznych obejściach, specyficznej obsłudze przypadków brzegowych i kodzie napisanym prosto na produkcję – w miejscach, których nikt nigdy nie udokumentował, a o których istnieniu wszyscy dawno zapomnieli.
Całkowite przepisanie systemu może mieć sens, ale dopiero na późniejszym etapie. Wybieranie tej opcji jako pierwszego kroku w całej modernizacji to z reguły ogromne ryzyko – zwłaszcza jeśli firma nie może pozwolić sobie na technologiczny przestój.
Kiedy całkowita wymiana oprogramowania ma sens biznesowy
Czasami modernizacja etapowa po prostu nie wystarcza. Niektóre moduły systemu są ze sobą tak mocno powiązane, kruche i źle zaprojektowane, że ich stopniowa naprawa całkowicie mija się z celem.
W takich sytuacjach jednorazowe przełączenie na nowe rozwiązanie (strategia big-bang) bywa uzasadnione. Musisz jednak zaplanować to jako ściśle kontrolowany proces, a nie skok w nieznane. Tam, gdzie to tylko możliwe, testuj nową logikę równolegle ze starą. Z góry określ warunki awaryjnego wycofania wdrożenia i zdefiniuj mierzalne kryteria sukcesu. Co najważniejsze: graj w otwarte karty. Jasno tłumacz zarządowi, co dokładnie wymieniacie, dlaczego modernizacja etapowa tu nie zadziała i z jakim konkretnie ryzykiem wiąże się to posunięcie.
Wymiana dużych obszarów systemu za jednym zamachem wcale nie musi zakończyć się katastrofą. Niesie jednak ze sobą tak duże ryzyko operacyjne i wymaga tak potężnych nakładów pracy, że każda decyzja o takim kroku musi być twardo uargumentowana biznesowo i perfekcyjnie zaplanowana.
Jak mierzyć sukces w ratowaniu projektów IT
Nie potrzebujesz ładnych dashboardów z próżnymi metrykami. Potrzebujesz twardych dowodów na to, że system staje się bezpieczniejszy i łatwiejszy w rozwoju.
Zamiast śledzić wszystko, skup się na kilku sprawdzonych w branży metrykach:
- Lead Time for Changes – ile czasu faktycznie mija od rozpoczęcia pracy nad zadaniem do wdrożenia go na produkcję?
- Change Failure Rate – jaki odsetek wdrożeń kończy się natychmiastową awarią lub powrotem starych błędów (regresją)?
- Maintenance Overhead – jaki procent czasu Twoi inżynierowie bezpowrotnie tracą na bieżące utrzymanie i gaszenie pożarów?
- Przewidywalność dostarczania (Predictability) – czy zespół faktycznie dowozi to, co zadeklarował na dany sprint?
- MTTR (Mean Time to Recovery) – jak szybko jesteście w stanie przywrócić system do działania, gdy w końcu coś pęknie?
W trakcie skutecznego ratowania projektu powinieneś zaobserwować wyraźny trend: Maintenance Overhead i CFR zaczynają spadać, a Lead Time stopniowo wraca do normy. Jeśli po wdrożeniu pierwszych zmian stabilizacyjnych te wskaźniki wciąż stoją w miejscu, to znak, że po prostu przepychasz problemy z miejsca na miejsce, zamiast leczyć ich przyczynę.
Plan ratunkowy przynosi realne, biznesowe efekty dopiero wtedy, gdy twarde dane potwierdzą faktyczną zmianę: wdrożenia nie niosą już ze sobą ogromnego ryzyka, zespół odzyskał pewność siebie, a dostarczanie nowych funkcji ostatecznie wygrywa z operacyjnym chaosem.
Kiedy wewnętrzna naprawa długu technicznego zawodzi
Niektóre zespoły potrafią samodzielnie ustabilizować i naprawić system. Innym ta sztuka się nie udaje.
Zazwyczaj przyczyną porażki nie jest brak umiejętności czy zaangażowania. Prawdziwy problem polega na tym, że ten sam zespół, który musi utrzymać system przy życiu, próbuje go jednocześnie przeprojektować pod ogromną presją czasu i oczekiwań biznesu. Równolegle inżynierowie reagują na awarie, wspierają codzienne wdrożenia i muszą nieustannie dowozić krótkoterminowe wyniki. W efekcie prace porządkowe ruszają, zacinają się i są odkładane na półkę w ułamku sekundy, gdy tylko na produkcji pojawi się kolejny krytyczny błąd.
Właśnie wtedy wsparcie z zewnątrz staje się najbardziej racjonalnym wyborem. Niezależne ratowanie projektu IT (Project Rescue) ma sens, gdy kolejne wewnętrzne próby uporządkowania kodu zawodzą, wiedza o architekturze spoczywa w głowach zaledwie kilku osób, a firma po prostu nie może pozwolić sobie na kolejną improwizowaną i nieskuteczną próbę spłacania długu technicznego.
Profesjonalny proces naprawczy zawsze zaczyna się od gruntownego audytu ryzyka technicznego i operacyjnego. Dopiero na tej podstawie przechodzi się do stabilizacji i etapowej modernizacji. Co ważne, przez cały ten czas architektura i nowy kod muszą być na bieżąco dokumentowane, a transfer wiedzy do Twojego zespołu powinien odbywać się w sposób ciągły. Głównym celem takich działań jest przywrócenie Ci pełnej kontroli nad systemem.
Co zrobić z niestabilnym systemem (kolejne kroki)
Twój kolejny krok zależy od skali problemu.
Jeśli dostrzegasz dopiero pierwsze sygnały ostrzegawcze, zaostrz zasady wdrożeniowe i jak najszybciej zabezpiecz kluczowe procesy. Jeśli jednak liczba błędów i czas marnowany na utrzymanie wyraźnie rosną, nie możesz pozwolić, by ten chaos stał się w Twojej firmie nową normą. Aby uzasadnić potrzebę zmian i ruszyć z modernizacją, musisz najpierw ubrać ten problem w liczby. Dobrym początkiem jest sprawdzenie, jak poprawnie wyliczyć rzeczywisty koszt długu technicznego – dzięki temu przekujesz ogólną frustrację zespołu w twarde, biznesowe argumenty.
Jeżeli system wciąż na siebie zarabia, ale z każdym miesiącem traci na stabilności, potrzebujesz głębszej diagnozy (warto sprawdzić np. 5 najczęstszych sygnałów ostrzegawczych przy rozwoju produktów IT). Gdy problem przestaje być punktowy i staje się wadą strukturalną, musisz dokładnie zrozumieć, z czym wiąże się profesjonalne przejęcie lub ratowanie projektu IT, zanim w ogóle rzucisz się w wir modernizacji.
Gdy system wciąż zarabia, ale wewnętrzne próby opanowania chaosu nieustannie lądują w martwym punkcie, nie ryzykuj przestojem. Zanim postawisz wszystko na jedną kartę – decydując się na kosztowne przepisanie kodu od zera czy kolejny prowizoryczny plan naprawczy – zacznij od niezależnej oceny sytuacji. Jeżeli Twój zespół tonie w bieżącym utrzymaniu i po prostu nie ma przestrzeni na bezpieczną, etapową modernizację, sprawdź nasze usługi w zakresie ratowania projektów technologicznych. Pomożemy Twoim inżynierom odzyskać kontrolę nad systemem, ustabilizować wdrożenia i wreszcie przywrócić realizację zadań z roadmapy – bez odcinania firmy od przychodów.
Podsumowanie
Największą pułapką długu technicznego jest to, że zazwyczaj dotyka on tych systemów, których firma po prostu nie może wyłączyć. Dopóki oprogramowanie przynosi zyski, biznes przymyka oko na słabą jakość kodu, a presja na zmiany wydaje się znikoma.
Tolerowanie tego bałaganu kończy się jednak zawsze tak samo: niezawodność drastycznie spada, wdrożenie jakiejkolwiek nowej funkcji zaczyna ciągnąć się tygodniami, a gaszenie narastających awarii na produkcji ostatecznie blokuje dalszy rozwój firmy.
Dlatego organizacje, które skutecznie wyszły z takiego kryzysu, nigdy nie czekały na totalną awarię. Nie porywały się też na ryzykowne przepisywanie wszystkiego od zera. Zamiast tego skupiły się na szybkiej stabilizacji i przemyślanej, etapowej modernizacji. Dzięki temu z wyprzedzeniem zredukowały ryzyko i odzyskały kontrolę nad oprogramowaniem. I to właśnie dlatego ostatecznie wygrały – bo przejęły inicjatywę, zanim przestarzały kod na dobre zaczął dyktować warunki biznesowi.




