Systemy legacy: czy warto przepisywać od zera z AI? Case study

| Disclaimer: Ten artykuł opisuje case study z realnego projektu i nie stanowi porady technicznej ani biznesowej. Decyzja o big rewrite, modernizacji stopniowej lub refaktoryzacji zależy od kontekstu Twojej organizacji. |
Pragmatic Meet to platforma do organizacji spotkań i wydarzeń branżowych — nasz własny produkt SaaS, na którym testujemy podejścia, które później wdrażamy u klientów z monolitycznym lub trudnym w utrzymaniu kodem legacy. W niecałe 2 miesiące przepisaliśmy ponad 94 000 linii kodu produkcyjnego systemu — bez zatrzymywania rozwoju produktu. W tym artykule wyjaśniamy, jak to zrobilismy, czego się nauczyliśmy, i czy było warto.
A w międzyczasie – zapisz się na webinar, w którym opowiemy o tym więcej.
Kiedy: 15.07.2026, godzina 18:00
Gdzie: Online, zapisy przez platformę Pragmatic Meet
Dlaczego open source przy przepisaniu legacy z AI najpierw spowalnia zespół?

Przepisanie legacy z AI w Pragmatic Meet stało się konieczne, bo szybki start na open source wyhodował własny dług techniczny — zanim w ogóle padła decyzja o big rewrite od zera.
Zamiast budować system od podstaw, oparliśmy produkt na gotowym rozwiązaniu open source. Logika była rozsądna: weź coś, co już działa, dostosuj i wypuść jak najszybciej. W praktyce rozpęd zamienił się w hamowanie. Trzy czynniki doprowadziły do tego, że „szybka modernizacja” wyhodowała własny kod legacy:
- Luka kompetencyjna i vibe-coding. Rozwiązanie open source było napisane w innym stacku technologicznym niż ten, który zna większość naszego zespołu. Zaczęliśmy pisać z pomocą AI kod, którego do końca nie rozumieliśmy — dziś nazwalibyśmy to vibe-codingiem. Kod legacy powstawał bez rygoru procesu, który później uznałem za sedno całej historii.
- Legacy code bez pełnego zrozumienia. System open source szybko stał się legacy naszej własnej roboty. Nie rozumieliśmy go w pełni — a to jedna z najuczciwszych definicji systemu legacy. Brakowało pełnego pokrycia testami, a te, które były, działały wolno. System był trudny w utrzymaniu.
- Martwy kod i regresje. Odziedziczyliśmy mnóstwo nieużywanego kodu. Próby jego usuwania często powodowały regresje podczas rozwoju — typowy problem przy monolicie z latami nakładanych zmian.
Ironia jest morałem tej części: zaadoptowaliśmy open source, żeby przyspieszyć, a sami się zatrzymaliśmy pod ciężarem legacy. Chcąc uniknąć budowania od zera, wyhodowaliśmy własny system legacy. Decyzja o przepisaniu zapadła szybko.
Od czego zacząć przepisanie legacy z AI — dokumentacja biznesowa przed kodem
Przepisanie legacy z AI musi zaczynać się od opisu biznesu, nie od linijki kodu — to pierwszy krok, który odróżnia udany big rewrite od kolejnego „przepisujemy wszystko” bez mapy.
Zanim ruszyliśmy z przepisywaniem Pragmatic Meet, sięgnęliśmy po wewnętrzne narzędzie do zarządzania wiedzą projektową (PKM – Projekt Knowledge Management) i opisaliśmy w nim procesy biznesowe, które realnie były dla nas ważne — wyciągnięte ze starego systemu legacy, ale niezależne od jego implementacji.
Kolejność wyglądała tak:
- Rozmowa o tym, co właściwie chcemy zbudować — wizja i strategia produktu.
- Nowe procesy biznesowe z warsztatów.
- Mapowanie ich na istniejącą implementację w legacy — czasem dokumentowane zwykłymi zrzutami ekranu.
Sens tego zabiegu jest jeden: PKM reprezentuje stronę biznesową w sposób niezależny od implementacji. Opis biznesu nie narzuca tego, jak później napiszemy kod. Ta dokumentacja staje się źródłem specyfikacji w podejściu Spec Driven Development (SDD) — metodzie, w której najważniejszym artefaktem jest specyfikacja, a pierwsze specyfikacje to specyfikacje biznesowe.
Przy przepisywaniu legacy z AI obowiązuje jedna zasada, która decyduje o jakości całego procesu: konwergencja bazy wiedzy. Baza wiedzy musi być zbieżna — jeden aktualny zestaw artefaktów, nie pięć wersji strategii produktowej wygenerowanych w pięciu rozmowach z asystentem AI. Jeden z najczęstszych błędów w pracy z AI to produkowanie zbyt wielu dokumentów. Reguła jest prosta: zawsze udoskonalaj to, co już masz, nigdy nie twórz nowego bytu bez potrzeby.
Każdy element dokumentacji biznesowej zestawiamy ze strategią produktu. Dzięki temu uzasadnienie biznesowe jest solidne — a specyfikacje, które z niego wynikają, mają sens przy przepisaniu legacy z AI, niezależnie od tego, czy wybierzesz big rewrite, czy stopniową modernizację systemu.
Dlaczego przepisanie legacy z AI wymaga Spec Driven Development?
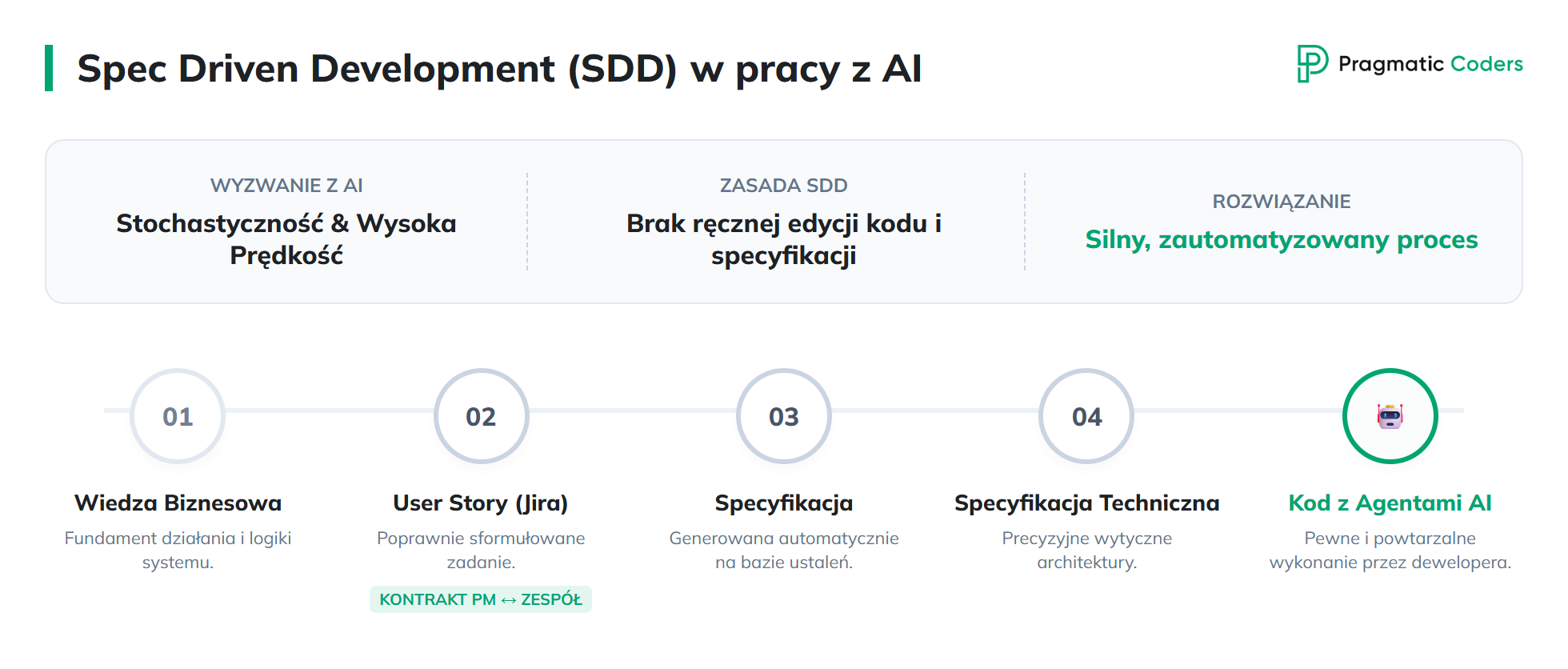
Przepisanie legacy z AI wymaga procesu silniejszego niż w tradycyjnym developmencie — bo agent AI jest stochastyczny (probabilistyczny i niedeterministyczny), a nie dlatego, że AI jest „słabe”.
Daj to samo zadanie stu osobom, a dostaniesz sto różnych wyników. Z agentem AI jest tak samo. Ludzkość od zawsze radziła sobie z nie-determinizmem przez proces — sprawdzony sposób robienia rzeczy. Z LLM-ami jest dokładnie tak samo, z jednym haczykiem: wszystko dzieje się znacznie szybciej. A skoro szybciej, proces musi być silniejszy.
Spec Driven Development (SDD) to proces, którego trzymamy się bardzo rygorystycznie przy przepisaniu legacy z AI. U nas „w pełni” znaczy konkretną rzecz: product manager nie edytuje specyfikacji ręcznie, a deweloperzy nie zmieniają kodu ręcznie. Jedno i drugie powstaje ze specyfikacji i zdefiniowanego procesu.
Pipeline wygląda tak:
wiedza biznesowa → user story w Jirze → specyfikacja → specyfikacja techniczna → wykonanie przez dewelopera (z agentami AI)
User story to kontrakt między PM a zespołem — miejsce, w którym ustalamy, jak wygląda poprawnie sformułowane zadanie przy przepisaniu systemu legacy.
To wyjaśnia coś, co z zewnątrz może wyglądać dziwnie: zanim powstał pierwszy feature, minął ponad tydzień. I tak miało być.
Dlaczego pierwszy sprint przy przepisaniu legacy z AI to proces, nie funkcja?
Pierwszy sprint przy przepisaniu legacy z AI nie powinien dowozić wartości biznesowej — powinien dowieźć niezerową przepustowość przez cały pipeline Spec Driven Development.
Celem pierwszego sprintu była jedna rzecz: cały proces SDD musi zadziałać end-to-end. Jedyna user story, którą dowieźliśmy, brzmiała: użytkownik może podać adres e-mail, utworzyć sesję i zobaczyć pusty ekran. Na powierzchni — minimum. Pod spodem — cały kod i wszystkie specyfikacje powstały automatycznie, przechodząc przez cały pipeline przepisania legacy z AI.
Z perspektywy product managera musieliśmy zrobić dwie rzeczy:
- Wziąć wiedzę biznesową — niezależną od implementacji — i zamienić ją w user stories.
- Stworzyć kontrakt z zespołem na to, jak wygląda poprawna user story.
Zanim cokolwiek mogło wyjść drugim końcem jako feature, najpierw musiały istnieć i realnie zadziałać specyfikacje oraz sam proces. Ten ponad tydzień to postawienie procesu — nie opóźnienie w dostarczaniu.
| Przed SDD + AI (refaktoryzacja / rozwój legacy) | Po przepisaniu legacy z AI | |
|---|---|---|
| Rozmiar user story | ~3 punkty (stały) | ~3 punkty (stały) |
| Sprint | 2 tygodnie | 1 tydzień |
| Stories na sprint (zespół ~4 os.) | ~8 / 2 tyg. ≈ 4/tydz. | ~14/tydz. |
| Przyspieszenie | — | ~3,5× (od 2. sprintu, stabilne) |
| Pierwszy deliverable | feature biznesowy | pusty ekran po zalogowaniu + działający pipeline |
Jak zarządzać kontekstem AI przy przepisaniu systemu legacy?
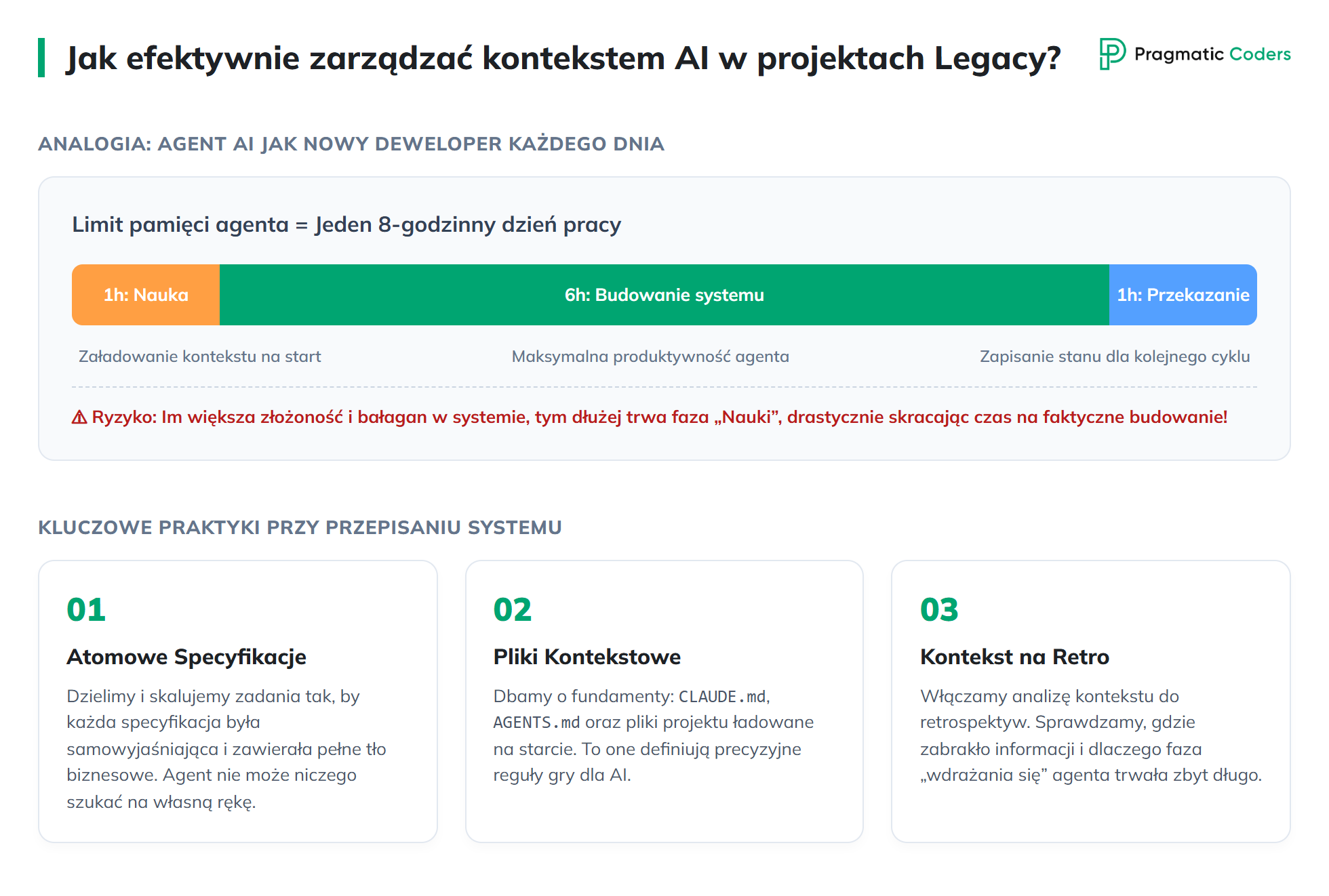
Przepisanie legacy z AI wymaga świadomego zarządzania kontekstem — to umiejętność, która okazała się decydująca, gdy zespół zaczął pracować znacznie szybciej niż przy utrzymywaniu starego kodu legacy.
Wyobraź sobie zespół z jednym deweloperem, ale każdego dnia dostajesz innego. Poniedziałek: Adam. Wtorek: Albert. Środa: Bernard. Każdy ma z tobą tylko jeden dzień — osiem godzin pracy to Twój kontekst. Godzina na naukę systemu. Sześć na budowanie. Ostatnia na przekazanie pracy następnemu.
Z agentami AI jest dokładnie tak samo — tylko szybciej. Im bardziej rośnie złożoność systemu po przepisaniu legacy, tym trudniej utrzymać „naukę” na poziomie jednej godziny.
Stąd konkretne praktyki przy przepisaniu legacy z AI:
- Tniemy i skalujemy specyfikację tak, żeby pojedyncza specyfikacja była maksymalnie samowyjaśnialna i zawierała tło biznesowe. Agent nie powinien niczego doszukiwać — wszystko musi być już w środku.
- Dopieszczamy pliki kontekstu — CLAUDE.md, AGENTS.md, plik projektu i wszystko, co ładuje się agentowi na starcie. To fundament przepisania legacy z AI, nie detal.
- Włączamy pliki kontekstu do retrospektywy. Tam patrzysz, gdzie kontekst nie był zarządzany i nauka na początku zadania trwała za długo — tracąc korzyść z „jednego dnia” pracy agenta.
Nie chodzi o antropomorfizowanie AI. Chodzi o uczciwe przyznanie, że jest komponent software’owo-sprzętowy, który współtworzy wynik przepisania legacy — i jeśli błędy zaczną się kumulować przy ograniczonym kontekście, z każdym „nowym deweloperem” każdego dnia robi się naprawdę trudno.
Jakie decyzje przy przepisaniu legacy z AI są najdroższe do cofnięcia?
Przepisanie legacy z AI zmienia ekonomię decyzji architektonicznych: gdy pisanie kodu przestaje być najwolniejszą częścią systemu, koszt cofnięcia niektórych decyzji rośnie dramatycznie.
Tradycyjnie, kiedy podejmowałeś decyzję przy refaktoryzacji lub modernizacji systemu legacy, miałeś czas, żeby się odleżała — implementacja i tak nadążała wolniej. W świecie, w którym zespół z AI i SDD porusza się szybko, błędna decyzja szybko dostaje piętnaście, dwadzieścia user stories zbudowanych na niej. Cofnięcie jest drogie.
Trywialny, ale czysty przykład z Pragmatic Meet: struktura URL-i i architektura informacji. Pracowaliśmy równolegle nad wieloma obszarami — nie budowaliśmy jednej funkcji, kończymy, bierzemy następną. To wymusiło zamknięcie pewnych decyzji już na samym początku przepisania legacy z AI. Wypchnięcie złej struktury adresów na produkcję jest potem koszmarem do odkręcenia — przekierowania, rozjeżdżająca się nawigacja, problemy SEO.
Dlatego krytyczną częścią przygotowania specyfikacji jest identyfikowanie decyzji i myślenie o koszcie ich cofania. Jeśli koszt jest wysoki — zajmij się nią świadomie: przetestuj wcześnie, przebuduj pracę tak, żeby nie musieć podejmować jej teraz, albo zwęź scope, żeby nie wpaść w króliczą norę.
Jak mierzyć prędkość zespołu przy przepisaniu legacy z AI?
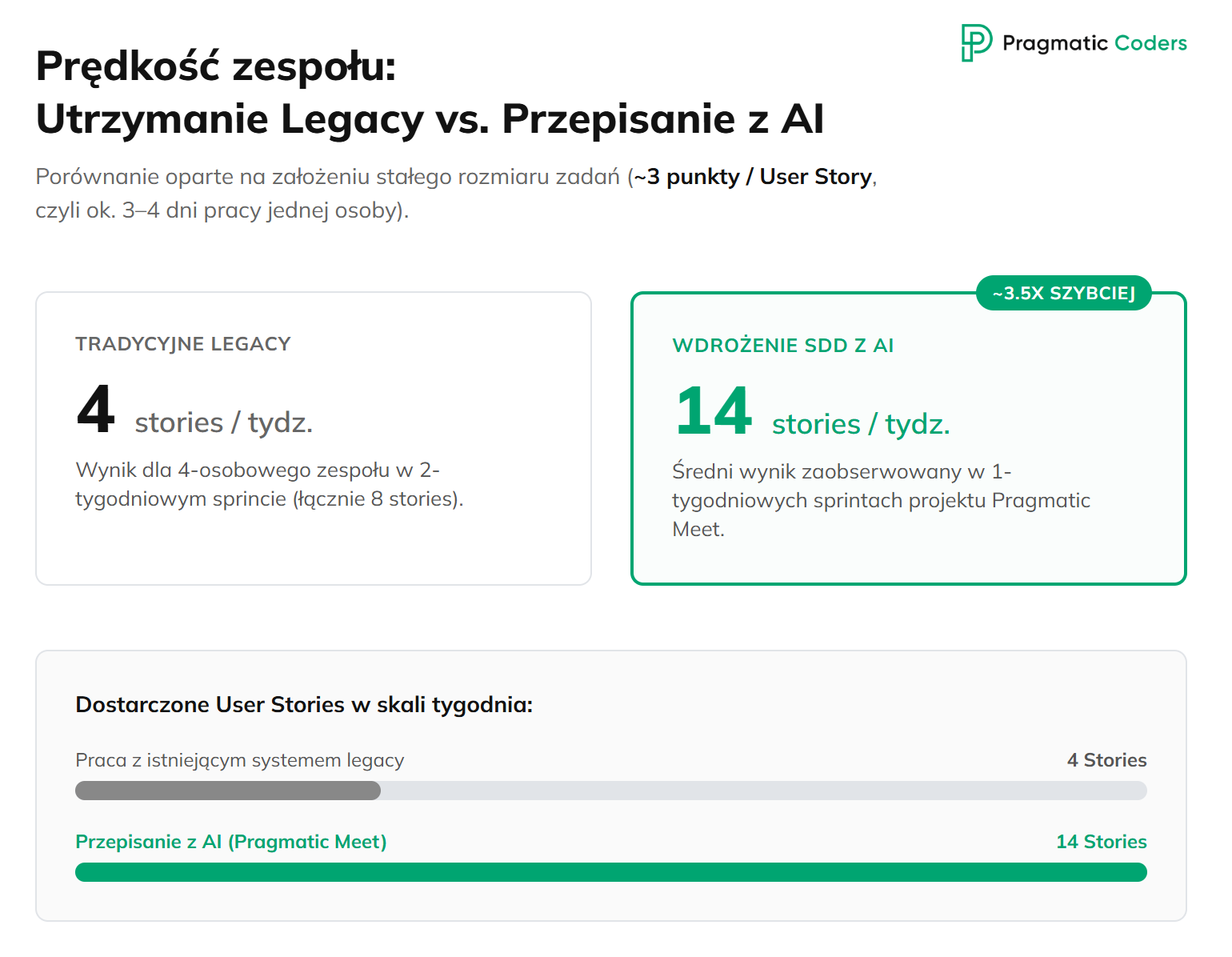
Prędkość zespołu przy przepisaniu legacy z AI da się mierzyć sensownie tylko wtedy, gdy user stories mają w miarę stały rozmiar — u nas około 3 punktów każda. Ta stałość czyni porównanie między utrzymywaniem starego kodu legacy a przepisaniem z AI wiarygodnym.
Punkt odniesienia z tradycyjnego świata: trzypunktowe story to zwykle 3–4 dni pracy jednej osoby. Czteroosobowy zespół w dwutygodniowym sprincie dowozi około 8 takich stories — czyli około 4 stories tygodniowo przy pracy z istniejącym systemem legacy.
Po wdrożeniu SDD z AI w Pragmatic Meet obserwujemy średnio 14 user stories na sprint przy sprintach jednotygodniowych — czyli około 14 stories tygodniowo. W zaokrągleniu ~3,5× szybciej niż przed przepisaniem. Uczciwie dodam, że krótszy sprint to większy narzut na spotkania. Co istotne: ta prędkość ustabilizowała się już od drugiego sprintu i była praktycznie stała przez cały okres pracy.
Same liczby nie mówią wszystkiego — ale bez nich łatwo wpaść w narrację o „mocy AI” zamiast o procesie, który tę moc kieruje przy przepisaniu legacy.
Czy przepisanie legacy z AI jest łatwiejsze niż budowa od zera?
Przepisanie legacy z AI nie jest łatwiejsze niż napisanie systemu od zera — to złe postawienie pytania, które często pada przy decyzji o big rewrite.
Żeby przepisać system legacy z AI, trzeba zaadresować różne rodzaje długu technicznego naraz: technologiczny, projektowy, dokumentacyjny, kompetencyjny, produktowy, biznesowy. W praktyce sprowadza się to do uporządkowania wszystkiego, co boli w starym kodzie legacy. To nie jest skrót względem greenfieldu.
Nie, wcale nie jest łatwiej. Ale potencjalnie kończysz w dużo lepszym miejscu niż przy samym utrzymywaniu monolitu — z procesem, dokumentacją, testami i kodem, który zespół rozumie.
Refaktoryzacja, modernizacja czy big rewrite — co wybrać zamiast przepisania legacy z AI?
Przepisanie legacy z AI to jedna z trzech głównych ścieżek przy trudnym kodzie legacy — wybór zależy od rodzaju długu technicznego, nie od tego, czy masz dostęp do ChatGPT czy Copilota.
| Podejście | Kiedy ma sens | Ryzyko |
|---|---|---|
| Refaktoryzacja | Dług jest lokalny, zespół rozumie system, architektura da się ratować | Powolna, ale bezpieczna |
| Modernizacja stopniowa | System musi działać bez przerwy, można migrować moduł po module | Długi kalendarz, dwie bazy kodu naraz |
| Big rewrite / przepisanie od zera | Dług systemowy (stack, testy, zrozumienie, martwy kod), koszt utrzymania > koszt przebudowy | Wysokie bez procesu (SDD, specyfikacje, pomiar) |
| Przepisanie legacy z AI | Jak big rewrite, ale z procesem i agentami AI przyspieszającymi wykonanie | Nie skraca diagnozy długu — skraca wykonanie po postawieniu procesu |
W Pragmatic Meet refaktoryzacja i modernizacja stopniowa nie wchodziły w grę: mieliśmy dług systemowy — obcy stack, brak zrozumienia kodu legacy, brak testów, martwy kod. Przepisanie legacy z AI było big rewrite z rygorystycznym procesem, nie „magicznym skrótem”.
Gdzie jest wąskie gardło po przepisaniu legacy z AI?
Przepisanie legacy z AI w Pragmatic Meet ujawniło nowe wąskie gardło — wniosek, który wychodzi daleko poza jeden projekt i dotyczy każdego zespołu, który przyspieszył kodowanie z AI.
Cały świat jest przyzwyczajony do tego, że pisanie kodu jest wolne. Kiedy stworzylismy zespół poruszający się szybko dzięki SDD i AI, pojawiło się tarcie tam, gdzie ten zespół potrzebował czegoś od innych: innych zespołów, infrastruktury, decyzji biznesowych.
Teoria ograniczeń mówi wprost: ograniczenie w zespołach deweloperskich po przepisaniu legacy z AI się zmieniło. Kiedyś było nim tempo kodowania. Już nim nie jest. Teraz wąskim gardłem może być:
- tempo podejmowania decyzji i ryzyko ich konsekwencji,
- tempo produkcji specyfikacji produktowej — PM pracuje niemal na równi z zespołem,
- zespół projektowy, infrastruktura, zależności międzyzespołowe.
Pojawiają się zupełnie nowe ograniczenia w przepustowości całego systemu dostarczania oprogramowania. To musi się przez jakiś czas ustabilizować — i dopiero wtedy widać, co było prawdziwym bottleneckiem po przepisaniu legacy z AI.
Kiedy warto przepisywać legacy od zera z AI, a kiedy modernizować stopniowo?
Przepisanie legacy z AI ma sens, gdy koszt utrzymania i rozwoju obecnego kodu legacy przewyższa koszt uporządkowania długu technicznego i przebudowy — a organizacja jest gotowa na proces, nie tylko na „szybsze pisanie kodu”. Modernizacja stopniowa ma sens, gdy system da się bezpiecznie rozwijać, zespół go rozumie, a dług jest lokalny. Refaktoryzacja wystarcza, gdy architektura jest zdrowa, a problem dotyczy wybranych modułów.
Dlaczego ponad tydzień bez pierwszego feature'a przy przepisaniu legacy z AI?
Ponad tydzień bez feature’a to czas na postawienie pipeline’u Spec Driven Development — specyfikacje, kontrakt na user story, automatyczne generowanie kodu i dokumentacji. Pierwszy deliverable przy przepisaniu legacy z AI to dowód, że proces działa end-to-end, nie że produkt jest gotowy.
Jak mierzyć, czy przepisanie legacy z AI realnie przyspiesza zespół?
Mierz prędkość na user stories o stałym rozmiarze (u nas ~3 punkty). Porównuj liczbę stories na tydzień przed i po — nie linie kodu, nie liczbę commitów. W Pragmatic Meet: ~4 stories/tydzień przy utrzymywaniu legacy → ~14 stories/tydzień po przepisaniu z AI, stabilnie od 2. sprintu.
Refaktoryzacja czy przepisanie legacy z AI — co szybsze?
Refaktoryzacja jest zwykle bezpieczniejsza, ale wolniejsza przy długu systemowym. Przepisanie legacy z AI nie jest szybsze na starcie (tydzień na proces), ale po ustabilizowaniu SDD dało nam ~3,5× wyższą przepustowość niż praca ze starym kodem legacy.
Czy AI zastępuje architekta i product managera przy przepisaniu legacy?
Nie. AI przyspiesza wykonanie przy przepisaniu legacy z AI — ale decyzje architektoniczne, specyfikacja biznesowa i zarządzanie kontekstem stają się ważniejsze. Wąskie gardło przesuwa się z kodowania na specyfikację, decyzje i zależności międzyzespołowe.
Ile trwa przepisanie legacy z AI w praktyce?
W Pragmatic Meet: ponad 94 000 linii kodu legacy przepisanych w niecałe 2 miesiące, bez zatrzymywania rozwoju produktu. Pierwszy tydzień to proces, nie funkcje — realny kalendarz big rewrite z AI jest dłuższy niż sugeruje sama liczba linii kodu.
Webinar live — cała historia z trzech perspektyw
15 lipca 2026, godz. 18:00 — bezpłatny webinar z Q&A o przepisaniu legacy z AI (case study Pragmatic Meet).
- Wiktor Żołnowski — decyzja o big rewrite, ryzyko, koszty z poziomu biznesu
- Bartek Czarnecki — proces SDD z AI od specyfikacji po produkcję
- Emil Rusin — codzienna praca dewelopera: gdzie AI przyspiesza przepisanie legacy, a gdzie nie
Pokażemy na żywo pracę ze specyfikacjami — od notatki głosowej po zaktualizowaną bazę wiedzy.
👉 Zapisz się na webinar: [LINK_ZAPISY]
Po webinarze — możliwość bezpłatnej konsultacji o Twoim kodzie legacy.




