Kiedy dostawca podnosi cenę o 700%. Jak bezpiecznie integrować 3rd party software

Tekst ma dwa poziomy. Sekcje główne są decyzyjne – dla osób, które wybierają dostawcę i odpowiadają za skutki tej decyzji. Podsekcje oznaczone zielonym tłem „Dla zespołów technicznych” zawierają konkretne wzorce wdrożeniowe. Jeśli odpowiadasz tylko za decyzję o dostawcy, podsekcje techniczne możesz pominąć. Jeśli pracujesz nad wpięciem dostawcy w produkt, czytaj wszystko.
Gdy dostawca podnosi cenę – kilka przykładów
W 2023 Broadcom kupił VMware – oprogramowanie, na którym przez dwie dekady opierały się centra danych większości dużych firm na świecie. Po przejęciu klienci dostawali oferty odnowienia z wzrostami cen w przedziale 25–700%. Dwa lata później tylko 4% klientów w pełni zmigrowało do alternatyw, a typowa migracja zajmuje 18–24 miesięcy (dane CloudBolt za TechRadar).
Alternatywy istniały. Migracja jednak nie była kosztem przeprogramowania – była kosztem przebudowy sposobu działania całej organizacji. Procedury administratorów, kompetencje zespołu IT, dziesiątki innych systemów postawionych na tej technologii – wszystko to zrastało się z VMware przez dwie dekady. Tego nie da się rozwiązać decyzją zarządu „migrujemy do alternatywy w 6 miesięcy”, bo to nie jest projekt informatyczny. To jest faktyczna zmiana w sposobie, w jaki firma działa na co dzień. Tego ryzyka nie da się ograniczyć żadnym chwytem inżynierskim, bo zależność nie żyje w kodzie. Żyje w procesach, w rękach zespołu, w produktach, które VMware obsługiwał po drodze.
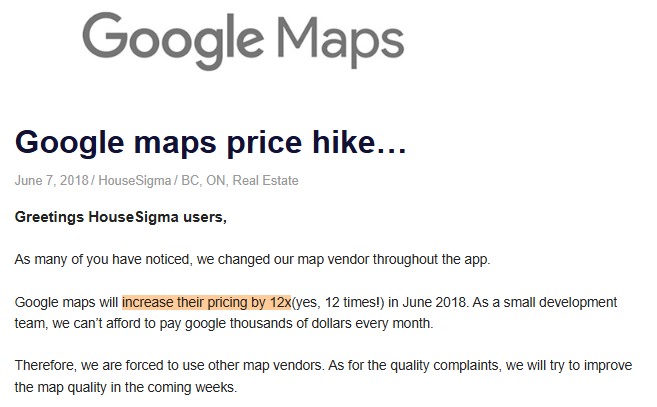
Drobniejsza, ale bardziej znana wersja tej samej historii zdarzyła się pięć lat wcześniej. W 2018 Google ogłosił nową politykę cenową dla Google Maps Platform i dał klientom 40 dni na dostosowanie się. Dla wielu z nich, zwłaszcza mniejszych firm, oznaczało to migrację w trybie awaryjnym. HouseSigma, kanadyjska aplikacja real estate, opublikowała post, w którym przyznała, że została zmuszona zmienić dostawcę map, że jakość po migracji spadła i że pracują nad jej poprawą w nadchodzących tygodniach (archiwum posta). Nie była to historia odosobniona; podobne komunikaty publikowali inni klienci Google Maps, od serwisów śledzących ruch lotniczy po wydziały akademickie (ADS-B Exchange, University of Washington).
HouseSigma nie wybrała źle. W swoim czasie wybrała najpopularniejsze rozwiązanie na rynku. Alternatywy istniały – Mapbox był wtedy firmą z 100 mln USD przychodu rocznego – tylko nikt nie zakładał, że trzeba się będzie pakować w 40 dni. Dostawca jednostronnie zmienił warunki, klient musiał ponieść koszt.
Decyzja o tym, którego dostawcę oprogramowania wybrać, nie jest decyzją techniczną. To decyzja o tym, ile ryzyka Twoja organizacja świadomie przejmuje na siebie – i jak głęboko jeden zewnętrzny gracz może wrosnąć w to, jak ta organizacja pracuje. Decyzja o tym, jak go wpiąć w produkt – już tak. Pierwsza zapada w sali zarządu, druga – w zespole inżynierskim. Obie kosztują, jeśli zostaną podjęte bez świadomości skutków.
Czym jest “bezpieczeństwo” w tym kontekście
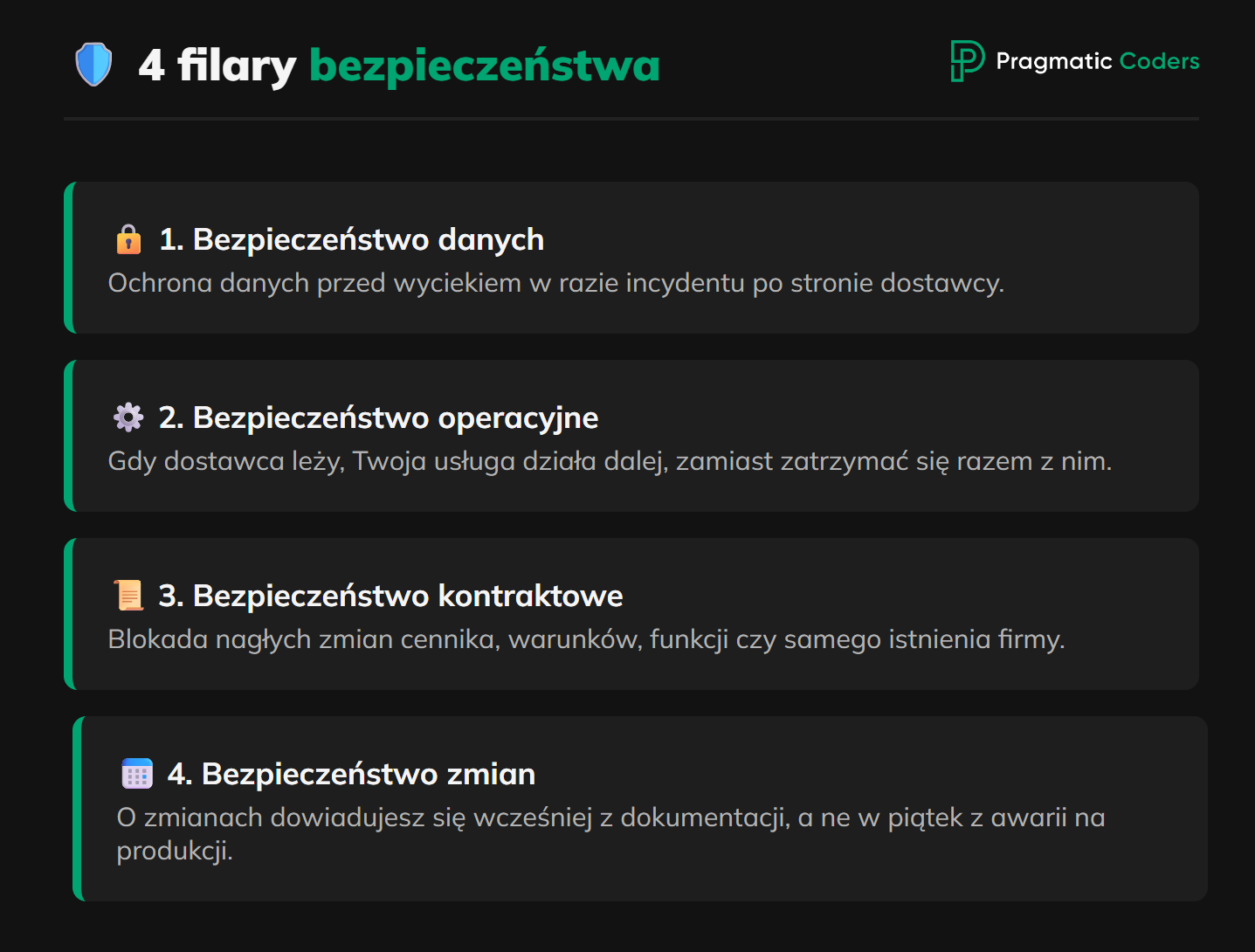
W tym artykule rozumiem przez „bezpiecznie” cztery rzeczy:
- Bezpieczeństwo danych – czy dane, które przekazujesz dostawcy, są u niego chronione i czy w razie incydentu po jego stronie nie wyciekną razem z nim.
- Bezpieczeństwo operacyjne – kiedy dostawca przestaje działać, czy Twoja usługa działa dalej, czy zatrzymuje się razem z nim.
- Bezpieczeństwo kontraktowe – co dostawca może zmienić bez Twojej zgody: cennik, warunki, zakres funkcji, samo istnienie firmy.
- Bezpieczeństwo zmian – czy o tym, że dostawca zmienia coś, co u Ciebie się zepsuje, dowiadujesz się wcześniej i z dokumentacji, czy w piątek po południu z awarii w produkcji.
Reszta artykułu to lista tego, co realnie można z tym zrobić – na poziomie decyzji przed wyborem dostawcy, na poziomie pytań, które warto zadać zespołowi przed wdrożeniem, i na poziomie scenariuszy, które warto zaprojektować, zanim awaria sama je wymusi.
Co sprawdzić, zanim wybierzesz dostawcę
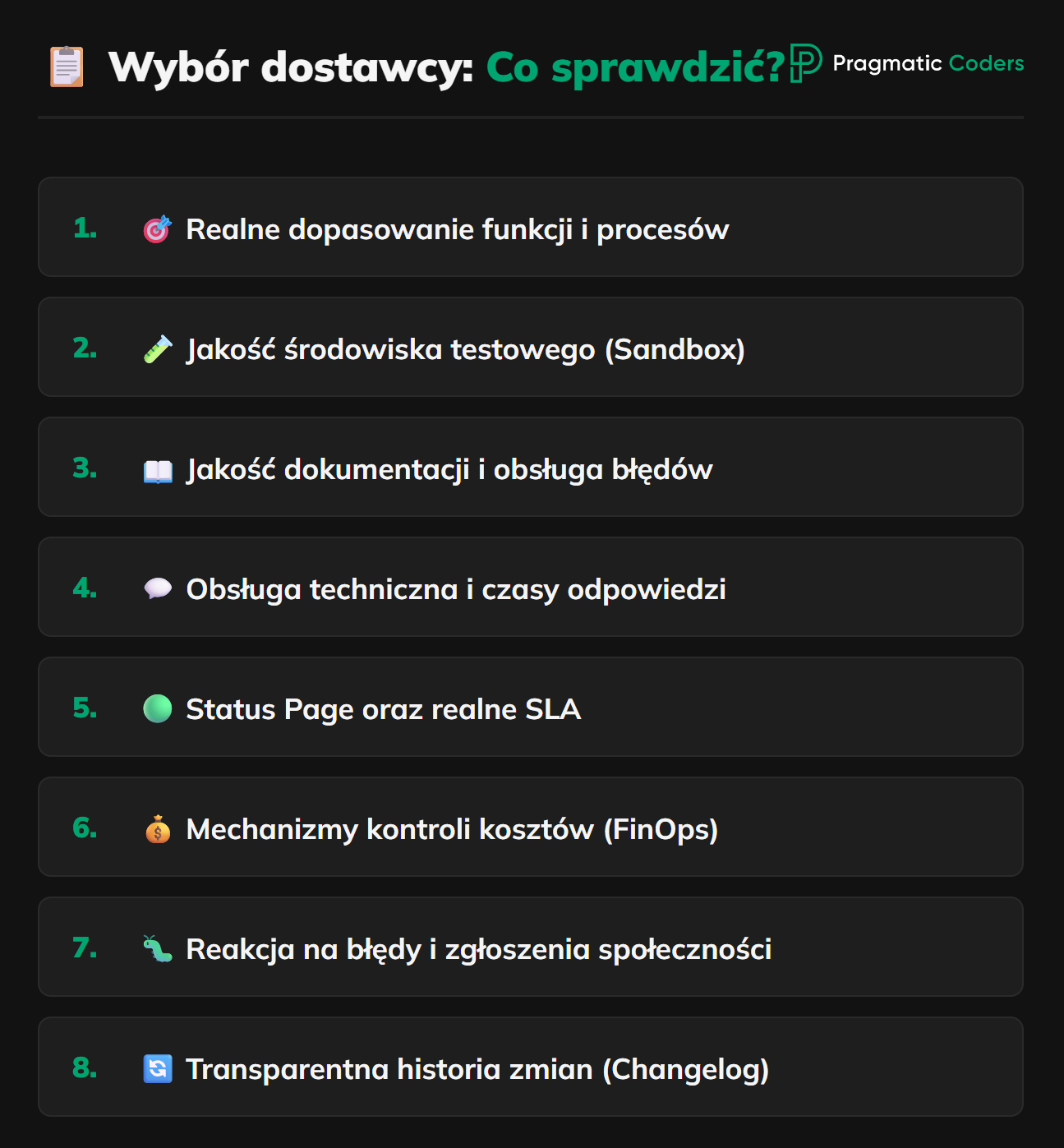
Lista rzeczy do weryfikacji w dokumentacji i w praktyce, w kolejności od tego, co najczęściej rozstrzyga decyzję.
1. Czy dostawca naprawdę robi to, czego potrzebujesz – w sposób, w jaki tego potrzebujesz.
To brzmi trywialnie, ale wymaga rozdzielenia dwóch warstw. Pierwsza: czy oferta funkcjonalna pokrywa Twoje wymagania. Druga, mniej oczywista: czy sposób, w jaki dostawca udostępnia te funkcje, da się sensownie wpiąć w Wasze codzienne procesy.
Przykład z mojego doświadczenia: jeden z naszych klientów wybrał regionalnego operatora płatności i dopiero w trakcie wdrożenia okazało się, że każdy nowy sklep trzeba dodać ręcznie w panelu dostawcy – nie da się tego zrobić automatycznie. Dla biznesu, który planował uruchamiać dziesiątki sklepów miesięcznie, oznaczało to, że automatyzacja onboardingu po prostu nie była możliwa. Sama funkcja istniała, ale w wersji, której procesy klienta nie były w stanie obsłużyć w skali.
Druga warstwa tego samego pytania to co dostajesz gotowe, a co Twój zespół musi dobudować samemu. To miejsce, w którym najwięcej projektów traci budżet, bo zakłada się, że dostawca obsługuje rzeczy „standardowe”. Standardowe dla jednego dostawcy bywa luksusem u innego – i przy podpisywaniu umowy tego się nie widzi. Widzi się dopiero, gdy zespół zaczyna pisać kod.
Każde takie ograniczenie da się dziś obejść po Waszej stronie. Tylko że każde z nich zostaje z Wami na lata. Przy skalowaniu i dodawaniu kolejnych funkcji koszt utrzymania tych obejść narasta, a w pewnym momencie staje się większy niż koszt wymiany dostawcy. Dlatego warto poprosić swój zespół techniczny o pisemną listę „czego dostawca nie obsługuje albo obsługuje gorzej, niż wynikało z prezentacji handlowej” – zanim podpiszesz umowę, nie po.
2. Środowisko testowe (sandbox) – i czas, żeby go realnie przeklikać.
Środowisko testowe to wersja systemu dostawcy, w której Twój zespół może bezpiecznie eksperymentować, zanim cokolwiek pójdzie na produkcję. Bez wpływu na prawdziwych klientów, prawdziwe dane, prawdziwe pieniądze.
Częstym błędem jest traktowanie tego jako prostego „checkboxa”: dostawca ma albo nie ma. W praktyce liczy się jakość. Czy środowisko testowe pozwala realnie odtworzyć Wasze najważniejsze scenariusze – w tym te nietypowe, błędne, brzegowe? W oficjalnej dokumentacji nie znajdziesz odpowiedzi na to pytanie. „Czego NIE da się zrobić” zwykle nie jest opisane. To wychodzi dopiero przy próbie.
Każdy dzień, w którym zespół naprawdę „przeklika” pełną współpracę z dostawcą w środowisku testowym, oszczędza tygodnie pracy nad obejściami po wdrożeniu. Krótszej ścieżki tu nie ma.
3. Jakość dokumentacji
Branża jest zbieżna co do tego, czego oczekiwać od dobrej dokumentacji dostawcy: szybki start, kompletny opis tego, co i jak można zrobić, działające przykłady, przewodniki zorganizowane wokół realnych scenariuszy, publicznie dostępna historia zmian, jasna polityka wycofywania funkcji. Stripe i Twilio są najczęściej cytowanymi wzorcami w branży.
Osobno warto zwrócić uwagę na opis tego, co się dzieje, gdy coś idzie nie tak. Sama lista możliwych błędów nie wystarcza – potrzebny jest opis, kiedy które błędy się pojawiają i co z nimi robić (dobry wzorzec to Stripe). W realnej współpracy z dostawcą więcej czasu poświęca się sytuacjom nietypowym niż ścieżce sukcesu. Brak takiej sekcji oznacza, że każdy nietypowy przypadek Wasz zespół odkryje dopiero wtedy, gdy on się stanie u klienta.
Praktyczny test, który możesz zrobić sam albo zlecić zespołowi: spróbujcie w godzinę znaleźć w dokumentacji odpowiedzi na 3–4 konkretne pytania z Waszego scenariusza („jak obsłużyć zwrot”, „co dzieje się, jeśli dostawca nie odpowie w czasie”, „jak sprawdzić, że to faktycznie dostawca, a nie ktoś podszywający się pod niego, wysłał nam informację o płatności”). Jeśli odpowiedzi nie ma – każde takie pytanie po wdrożeniu skończy się czekaniem na wsparcie dostawcy i kilkoma dniami zablokowanej pracy Waszego zespołu.
4. Jakość obsługi technicznej i czasy odpowiedzi
Podczas wdrażania Stripe u jednego z naszych klientów pierwsza linia wsparcia odpowiadała bardzo szybko na czacie. Jeśli nie miała informacji, kierowała pytanie do swoich programistów, którzy wracali mailowo z konkretną odpowiedzią. Sposób, w jaki dostawca obsługuje takie pytania, bezpośrednio przekłada się na to, ile czasu Twój zespół spędzi zablokowany przy nietypowym problemie. Najprostszy test: zanim podejmiesz decyzję o dostawcy, wyślij mu 2–3 realne pytania techniczne i zobacz, co dostaniesz w odpowiedzi. Jeśli odpowiedź brzmi „przeczytaj sekcję X dokumentacji” (którą już ktoś u Ciebie przeczytał), już wiesz, czego się spodziewać po wdrożeniu.
5. Status page i SLA
Status page powie Ci więcej o dostawcy niż jego strona marketingowa. Sprawdź historię incydentów z ostatnich 6–12 miesięcy: jak często coś nie działało, jak długo trwało, jak to komunikowali. Brak status page albo „zawsze zielony” status page mimo realnych awarii to sygnał ostrzegawczy. SLA czyta się jako uzupełnienie tej historii, nie jej zamiennik – obietnica 99,9% dostępności na papierze i 97% realnej dostępności na status page to dwie różne historie. Dobry status page realnie raportuje incydenty z datami, opisem zakresu i komunikacją w trakcie – status.stripe.com jest sensownym punktem odniesienia. Jeśli status page dostawcy przez wiele miesięcy pokazuje 100% uptime na wszystkim, prawdopodobnie nie patrzysz na realny obraz dostępności – tylko na to, co dostawca zdecydował się tam pokazać.
6. Mechanizmy kontroli kosztów po stronie dostawcy
Jeśli dostawca rozlicza się od każdego wywołania albo każdej operacji – sprawdź, jakie zabezpieczenia oferuje przed niekontrolowanym wzrostem rachunku. Trzy rzeczy, których warto szukać:
- Twardy limit – po przekroczeniu zdefiniowanej kwoty dostawca przestaje świadczyć usługę zamiast naliczać dalej (OpenAI, Anthropic).
- Alerty kosztowe – powiadomienia e-mail lub SMS, które informują, gdy Twoje wydatki przekroczą np. 50%, 80% czy 100% ustalonego budżetu. Samo powiadomienie nie blokuje dalszych wydatków – to tylko sygnał ostrzegawczy (np. AWS Budgets, rozwiązanie stosowane przez większość dostawców).
- Dashboard kosztów w czasie zbliżonym do rzeczywistego – minimum higieniczne.
AWS to najbardziej znany przykład dostawcy bez uniwersalnego twardego limitu – możesz wydać u niego dowolną kwotę. Brak któregokolwiek z tych mechanizmów oznacza, że jeden błąd w Waszym systemie albo zewnętrzny atak na publicznie dostępną część Waszej aplikacji mogą wygenerować rachunek proporcjonalny do skali ruchu, bez żadnej automatycznej granicy.
7. Jak dostawca reaguje na zgłaszane błędy
Wielu dostawców prowadzi publiczną listę błędów zgłaszanych przez społeczność, zwykle w serwisie Github. Poproś swój zespół, żeby na nią spojrzał. Ile jest otwartych zgłoszeń. Jak szybko ludzie dostawcy na nie odpowiadają. Czy odpowiadają konkretem, czy odsyłają do dokumentacji. Czy zgłoszenia nie wiszą tygodniami bez żadnej reakcji.
To mówi Ci, co się stanie, gdy Twój zespół zgłosi swój problem. Jest to też drugie źródło informacji o jakości wsparcia – niezależne od tego, co dostajesz w odpowiedzi handlowej. Publiczne, datowane, niefiltrowane przez dział marketingu.
8. Historia zmian
Publicznie dostępna i datowana historia zmian mówi Ci, że dostawca traktuje swoje oprogramowanie jak produkt, a nie jak coś, co czasem się po cichu zmienia. Stripe jest sensownym punktem odniesienia: każda zmiana opisana, daty znane, zmiany, które wymagają wysiłku po stronie klienta, wydzielone z osobnymi przewodnikami. Brak takiej historii oznacza, że o zmianach Twój zespół dowie się z maila do administratora konta – jeśli ten mail dotrze do właściwej osoby i zostanie przeczytany na czas.
Nie pozwól, żeby dostawca wrósł w Twój produkt
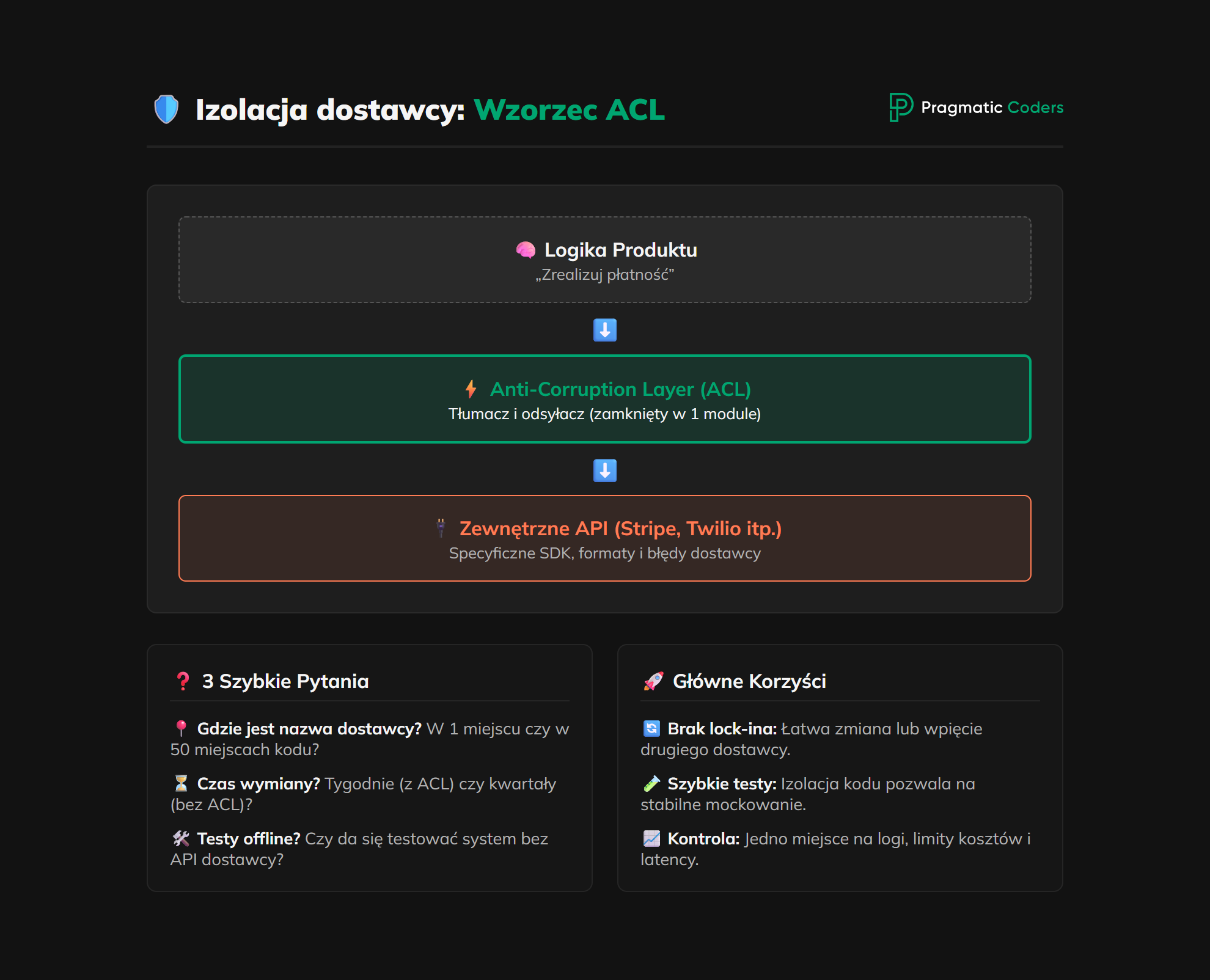
Wybór dostawcy to decyzja na dziś. Sposób, w jaki Twój zespół go „wpina” w produkt, to decyzja na lata.
Są dwa skrajne sposoby. Pierwszy: produkt “rozmawia” z dostawcą wprost. Wszędzie, gdzie potrzebne są jego usługi, w kodzie pojawia się jego nazwa, jego pojęcia, jego sposób działania. Tani i szybki w budowie. Wymiana dostawcy za 2 lata: projekt na kwartały.
Drugi: między produktem a dostawcą stoi cienka warstwa tłumacząca. Wasz produkt mówi własnym językiem („zrealizuj płatność”, „wyślij maila”, „pokaż mapę”), warstwa zna szczegóły konkretnego dostawcy i to ona je tłumaczy. Trochę droższy w budowie. Wymiana dostawcy za 2 lata: projekt na tygodnie.
To jest standardowy temat architektoniczny. Nie musisz znać szczegółów. Wystarczy, że wymusisz, by Twój zespół o tym świadomie zdecydował – zanim napisze pierwszą linię kodu. Trzy pytania, na które warto uzyskać odpowiedź przed wdrożeniem:
- Czy w naszym systemie nazwa dostawcy występuje w jednym miejscu, czy w pięćdziesięciu? To jedno pytanie mówi Wam, ile zajmie wymiana.
- Jeśli będziemy musieli zmienić dostawcę za 2 lata, jaki to jest projekt – tygodnie, miesiące czy kwartały? Odpowiedź powinna być znana, zanim ten moment nastanie. Nie po fakcie.
- Czy testy naszego systemu da się uruchomić bez prawdziwego połączenia z dostawcą? Jeśli nie, każda awaria dostawcy blokuje pracę zespołu, a każda zmiana w produkcie wymaga sprawnego dostawcy.
Ta sama decyzja architektoniczna upraszcza też kilka mniej oczywistych rzeczy w przyszłości: dodanie drugiego dostawcy na wypadek awarii pierwszego, reakcję na zmiany po stronie dostawcy, monitoring kosztów. Jeśli właśnie wdrażacie nowego dostawcę, warto poprosić swojego architekta lub kierownika technicznego, żeby ten temat omówił z zespołem przed startem prac, nie po nich.
Dla zespołów technicznych: anti-corruption layer w praktyce
Wzorzec opisany powyżej w środowisku integracyjnym ma swoją nazwę – anti-corruption layer (ACL). Pochodzi z książki Erica Evansa „Domain-Driven Design” (2003) i jest standardową odpowiedzią na pytanie „jak nie związać się z dostawcą na śmierć”.
Mechanizm sprowadza się do jednego: logika biznesowa nie wie o istnieniu dostawcy. Komunikuje się z warstwą pośrednią, która udostępnia własne abstrakcje – PaymentProcessor, EmailSender, MapsProvider – z metodami opisanymi w domenie. Dopiero w środku tej warstwy żyje SDK dostawcy, jego modele danych i jego semantyka. Wszystkie szczegóły dostawcy są zamknięte w jednym module.
Co konkretnie ta warstwa odcina od reszty aplikacji:
- Komunikację z dostawcą – wywołania HTTP, autoryzację, retry, timeouty, obsługę błędów. Tylko warstwa ACL zna nazwy endpointów, formaty żądań i strukturę odpowiedzi.
- Modele danych dostawcy – stripe.PaymentIntent, stripe.Customer z ich konkretnymi polami. Logika biznesowa widzi tylko Payment, Customer we własnych typach, z polami, które mają sens dla domeny.
- Semantykę dostawcy – fakt, że Stripe rozróżnia payment_intent.succeeded od charge.succeeded, że subskrypcja ma stan incomplete przez 23 godziny, że refund działa inaczej dla różnych metod płatności. ACL tłumaczy te szczegóły na pojęcia z domeny: „płatność się udała”, „subskrypcja aktywna”, „zwrot wykonany”.
Wymiana dostawcy to najbardziej oczywista korzyść, ale nie jedyna. Ta sama warstwa rozwiązuje też:
Testy bez prawdziwego dostawcy – w testach jednostkowych logiki biznesowej nie musisz wołać prawdziwego API ani uruchamiać sandboxa. Mockujesz interfejs PaymentProcessor. Testy są szybkie, deterministyczne i działają offline.
Dodanie drugiego dostawcy równolegle – jeśli kiedyś będziesz chciał mieć multi-provider dla emaila albo SMS, masz już połowę roboty zrobioną. Nowa implementacja interfejsu, logika biznesowa bez zmian.
Zmiana wersji API dostawcy – breaking change w API Stripe oznacza zmianę w jednym module, nie w całej aplikacji.
Punkt do obserwowalności i kontroli – jedno miejsce, w którym logujesz wszystkie wywołania dostawcy, mierzysz latencję, dodajesz circuit breaker, wpinasz retry. Nie musisz tego rozsiewać po kodzie.
Pytania do zadania zespołowi przed wdrożeniem
Większość incydentów po wdrożeniu nowego dostawcy bierze się z bardzo powtarzalnej listy problemów. Nie musisz znać szczegółów technicznych, żeby wymusić jakość. Wystarczy, że wiesz, jakie pytania zadać, zanim coś trafi do produkcji. Jeśli na któreś z poniższych zespół nie ma jasnej odpowiedzi – to jest właśnie ryzyko, które warto zaadresować przed startem, nie po.
- Co się dzieje, kiedy dostawca odpowiada wolniej niż zwykle? Wolniejszy dostawca, jeśli zespół nie ustawi sensownego limitu czasu oczekiwania, może zatrzymać cały Wasz system, nie tylko jego fragment. Klient widzi wolno działającą aplikację – chociaż popsuło się coś u dostawcy.
Dla zespołów technicznych: domyślne wartości popularnych klientów HTTP to albo brak limitu (axios w Node.js, Python requests, Go http.Client), albo limit absurdalnie wysoki z perspektywy aplikacji obsługującej użytkowników (fetch: 5 minut w Chrome i Node.js). Bez jawnego timeoutu zapytania do zewnętrznego serwisu, który zaczyna wolno odpowiadać, wiszą w aplikacji minutami zamiast milisekundami – w Node.js, gdzie liczba jednoczesnych zapytań może rosnąć w nieskończoność, oznacza to nieskończenie rosnący backlog operacji, których logika biznesowa nigdy nie domknie.
- Co się dzieje, jeśli wyślemy dostawcy to samo zlecenie dwa razy? Sieć jest zawodna. Wasz system wysyła zlecenie, nie dostaje potwierdzenia, próbuje jeszcze raz. Bez właściwego mechanizmu po stronie zespołu (i czasem dostawcy) to się kończy zdublowaną płatnością, zdublowanym zamówieniem albo dwoma mailami do klienta.
Dla zespołów technicznych: tu działają dwa wzorce równolegle. Po pierwsze – retry z backoffem, najlepiej wykładniczym: ponawianie zapytania w stałym, krótkim interwale generuje ruch wprost proporcjonalny do liczby instancji aplikacji i przy przejściowym problemie dostawcy potrafi wielokrotnie zwielokrotnić normalny ruch, przedłużając jego niedostępność lub powodując throttling Twojego konta. Po drugie – klucze idempotentności: jeśli dostawca je udostępnia (a wiele nie udostępnia), klient musi je wysyłać. Bez tego ponawianie po błędzie tworzy duplikat operacji nawet wtedy, gdy dostawca wykonał operację za pierwszym razem, a tylko jego odpowiedź się zgubiła.
- Co się dzieje, kiedy dostawca odpowiada „OK”, ale tak naprawdę nie wykonał operacji? Niektórzy dostawcy raportują błąd w nietypowy sposób – tak, że na pierwszy rzut oka odpowiedź wygląda jak sukces, choć w środku jest informacja o niepowodzeniu. Zespół musi wiedzieć, jak dany dostawca to robi, i celowo na to patrzeć.
Dla zespołów technicznych: część API zwraca błędy w treści odpowiedzi przy statusie HTTP 200 – {“success”: false, “error”: “…”} z kodem 200. Standardowe biblioteki HTTP traktują 200 jako sukces, więc kod, który nie sprawdza treści odpowiedzi, uznaje operację za udaną. Jak dokładnie wygląda to u danego dostawcy – kiedy zwraca błąd w body, kiedy w kodzie HTTP, kiedy w nagłówku – wynika z jakości dokumentacji. Jeśli dostawca nie ma osobnej sekcji o obsłudze błędów (jak Stripe), tych rzeczy uczysz się przez incydent.
- Skąd się dowiemy, że konkretny dostawca przestał działać, zanim zgłoszą to klienci? Standardowy monitoring Waszej aplikacji nie zawsze obejmuje to, co dzieje się po stronie zewnętrznego dostawcy. Dla każdego krytycznego dostawcy warto mieć osobny pulpit i alerty.
Dla zespołów technicznych: standardowe metryki aplikacji (czas odpowiedzi, error rate) dotyczą Twoich endpointów. Czas odpowiedzi i błędy zewnętrznych integracji trzeba świadomie instrumentować – metryki per dostawca, alerty na wzrost latencji i błędów. Bez tego degradacja po stronie dostawcy jest niewidoczna do momentu, gdy klient zgłosi reklamację.
- Co się stanie, jeśli ktoś podszyje się pod naszego dostawcę? Wielu dostawców wysyła do Waszego systemu informacje o zdarzeniach („klient zapłacił”, „transakcja anulowana”). Bez weryfikacji, że wiadomość naprawdę przyszła od dostawcy, każdy z zewnątrz, kto pozna jej format, może wysłać własną. To realny wektor nadużyć, jeśli zespół o tym nie pomyśli – ktoś może np. „potwierdzić” płatność, której nikt nigdy nie wykonał.
Dla zespołów technicznych: endpoint przyjmujący webhooki jest publicznie dostępny pod URL, który dostawca otrzymał i którego nikt nie pilnuje jak hasła. Bez weryfikacji podpisu HMAC (lub innego mechanizmu udostępnionego przez dostawcę) nie ma technicznej różnicy między żądaniem od dostawcy a żądaniem od dowolnego innego nadawcy znającego URL.
- Co się stanie, jeśli dostawca po dłuższej awarii prześle nam naraz wszystkie zaległości z 3 godzin? To realny scenariusz po każdej dłuższej awarii dostawcy. Jeśli Wasz system obsługuje takie zaległości od razu, lawina informacji może go położyć dokładnie w momencie, w którym dostawca wraca do sprawności. Standardowa odpowiedź: zaległości trafiają najpierw do wewnętrznej kolejki, dopiero z niej są obsługiwane w tempie, które Wasz system wytrzymuje.
Dla zespołów technicznych: wzorzec, w którym endpoint HTTP odbierający webhook wykonuje od razu pełną logikę biznesową (zapis zamówienia, wysłanie maila, aktualizacja stanu), łączy dwa systemy synchronicznie: czas odpowiedzi Twojego endpointu wpływa na to, czy dostawca uzna dostarczenie za udane. Bezpieczny wzorzec: endpoint robi tylko dwie rzeczy – weryfikuje podpis i wrzuca payload do własnej kolejki. Odpowiada 200 w milisekundach. Faktyczna logika dzieje się w konsumerach kolejki, asynchronicznie, z retry i DLQ po Twojej stronie. Wtedy lawina webhooków po incydencie dostawcy (np. Stripe wysyła 3-dniowy backlog w 10 minut po odzyskaniu dostępności) trafia do kolejki, nie do Twojej logiki biznesowej.
- Co się stanie, kiedy nasze klucze dostępu do dostawcy wygasną? Część dostawców wystawia poświadczenia z ograniczonym czasem życia. Bez aktywnego pilnowania ich dat wygaśnięcia, współpraca działająca rok przestaje działać z dnia na dzień bez żadnej zmiany po Waszej stronie. Po prostu pewnego dnia.
Dla zespołów technicznych: dotyczy to OAuth z refresh tokenami, kluczy API z TTL, certyfikatów do podpisywania webhooków. Każdy z tych typów poświadczeń wymaga osobnego mechanizmu monitoringu daty wygaśnięcia – z odpowiednim wyprzedzeniem alertu, żeby był czas na rotację.
- Jak monitorujemy, że oprogramowanie dostawcy nie stanie się luką bezpieczeństwa? Oprogramowanie dostawcy, którego używa Twój zespół, samo z siebie korzysta z dziesiątek innych „cegiełek” napisanych przez kogoś jeszcze. Zdarzało się – i to wielokrotnie w ostatnich latach – że któraś z tych cegiełek została po cichu przejęta przez atakującego i rozesłała złośliwy kod do tysięcy firm na świecie. Te firmy w ogóle nie wiedziały, że ten kod u nich działa. Higiena, której warto wymagać od zespołu: automatyczne narzędzia ostrzegające o znanych podatnościach w używanych komponentach i procedura szybkiej reakcji na alerty.
Dla zespołów technicznych: instalując SDK przez menedżera pakietów (npm, pip, maven), pobierasz nie tylko jego kod, ale i wszystkie jego zależności. Każda z tych paczek może zostać skompromitowana – publicznie udokumentowane przypadki: event-stream 2018, ua-parser-js 2021, debug i chalk we wrześniu 2025. Podstawowa higiena to pinowanie wersji w lockfile, automatyczny skan zależności w CI (npm audit, Snyk, Socket, Dependabot) i świadome ograniczanie ich liczby. Głębsze omówienie: OWASP Software Supply Chain Security Cheat Sheet.
Powyższa lista to nie kompletny test wdrożeniowy. To pytania, na które każdy z Twojego zespołu powinien umieć odpowiedzieć dwoma zdaniami, zanim współpraca z dostawcą trafi do produkcji. Brak odpowiedzi na którekolwiek z nich nie jest powodem, żeby blokować wdrożenie. Jest powodem, żeby świadomie podjąć decyzję, że akceptujesz to ryzyko.
Chcesz przejść przez taką ocenę całościowo?
Powyższe 8 pytań dotyczy współpracy z konkretnym dostawcą. Pełna samoocena stanu technicznego produktu obejmuje 60 punktów w 6 obszarach: architektura, testy, CI/CD, obserwowalność, dane, bezpieczeństwo. Każdy punkt to jedna konkretna praktyka i konkretne ryzyko, któremu zapobiega.
Pobierz Technical Health Checklist i przejdź przez nią z zespołem.

Co się dzieje, gdy dostawca jest niedostępny
Pytanie „co się dzieje z naszym systemem, gdy dostawca X przestaje odpowiadać” warto zadać przed wdrożeniem, nie podczas pierwszej awarii. Odpowiedź zaprojektowana na spokojnie wygląda inaczej niż ta podejmowana o trzeciej w nocy, z dostępnych w danej chwili opcji, pod presją wsparcia i klientów.
Trzy pytania, które warto zadać dla każdego dostawcy z osobna, zanim trafi do produkcji:
Czy nasz system działa, gdy ich nie ma? To wymusza podział dostawców na krytycznych i niekrytycznych – ale to nie jest podział techniczny, tylko biznesowy. Dostawca płatności, bez którego nie domykamy sprzedaży, jest krytyczny i wymaga innego planu na awarię niż system analityczny, który raz dziennie wzbogaca raport dla działu marketingu.
Co widzi klient? Pusta strona, błąd „coś poszło nie tak”, komunikat „funkcja chwilowo niedostępna”, a może w ogóle nie zauważa? To jest decyzja projektowa, którą się podejmuje przy planowaniu współpracy z dostawcą, a nie w trakcie incydentu o trzeciej w nocy. Czasem świadomy komunikat o awarii jest lepszy niż próba kontynuowania działania – lepiej powiedzieć klientowi „spróbuj za 10 minut”, niż obciążyć go dwa razy i tłumaczyć się dzień później.
Co się dzieje z zaległymi operacjami, gdy dostawca wróci? Czy odzyskamy stan, który próbowaliśmy z nim wymienić? Czy mamy kolejkę nieprzetworzonych zdarzeń, którą puścimy w momencie powrotu? Czy akceptujemy utratę i poprosimy klienta o powtórzenie operacji?
Standardowe rozwiązania
Standardowe sposoby radzenia sobie z powyższymi sytuacjami:
- Wyłącznik bezpieczeństwa (circuit breaker) – kiedy dostawca przestaje odpowiadać, Wasz system przestaje go obciążać kolejnymi próbami i od razu zwraca błąd po swojej stronie. To pozwala dostawcy odzyskać sprawność, a Wam nie obciążać własnego systemu zapytaniami, które i tak nigdzie nie dojdą.
- Praca w tle (kolejka asynchroniczna) – jeśli operacja nie musi być wykonana w sekundę, niech poczeka, aż dostawca wróci do sprawności. Klient widzi „dziękujemy, zajmiemy się tym”, a operacja faktycznie wykonuje się w tle.
- Lokalna kopia ostatniej znanej wartości (cache) – dla danych, które nie muszą być świeże co do sekundy (np. lista metod płatności dostępnych dla danego sklepu), wystarczy zachować ostatnią znaną wersję i pokazać ją klientowi, nawet jeśli dostawca chwilowo milczy.
- Wyłączenie funkcji w widoczny sposób (graceful degradation) – schowaj funkcję, która zależy od niedostępnego dostawcy, zostaw resztę aplikacji żywą. Lepiej, gdy klient nie widzi opcji „zapłać kartą”, niż gdy widzi ją i dostaje błąd po kliknięciu.
- Drugi dostawca jako zapasowy (multi-provider / fallback) – realnie skonfigurowany, gotowy do przełączenia. Drogie i skomplikowane. Robione tam, gdzie koszt godziny przestoju przekracza koszt utrzymania dwóch dostawców równolegle. Standardowo stosowane dla maili transakcyjnych, SMS-ów, DNS-ów, sieci dostarczania treści (CDN). Rzadziej dla płatności (choć i tu istnieje już cała kategoria produktowa „payment orchestration”, wyspecjalizowana w przełączaniu między operatorami).
Decyzja jest biznesowa, nie techniczna
Drugi dostawca dla newslettera wysyłanego raz w tygodniu to przesada. Brak jakiegokolwiek zabezpieczenia dla dostawcy obsługującego checkout w dużym sklepie może być świadomą decyzją – lepiej stracić godzinę sprzedaży niż obsługiwać potem błędy wynikające ze złego planu na awarię i rozjazdy danych między Waszym systemem a dostawcą. Ale to musi być świadoma decyzja, nie efekt zaniechania.
Trzeba też powiedzieć wprost: każdy z powyższych mechanizmów kosztuje pracę zespołu. Lokalna kopia danych personalizowanych dla każdego klienta jest trudna do zrobienia sensownie. Praca w tle w procesie, który musi dać klientowi odpowiedź natychmiast, wymaga przeprojektowania samego doświadczenia użytkownika. Drugi dostawca jako zapas dla rozbudowanej współpracy to często projekt na kwartały.
Świadoma decyzja „akceptujemy, że jeśli dostawca jest niedostępny, my również – bo koszt zabezpieczenia jest wyższy niż koszt incydentów” jest w pełni dopuszczalna. Różnica między tą decyzją a brakiem decyzji sprowadza się do tego, czy ktoś w organizacji świadomie zgodził się na ten scenariusz przed wdrożeniem – nie po pierwszej awarii.
Stoisz właśnie przed taką decyzją?
Wybór nowego dostawcy, ocena ryzyka istniejącej zależności, projektowanie integracji, która ma przetrwać kolejne 5 lat – w każdej z tych sytuacji pomaga drugie spojrzenie kogoś, kto przeszedł przez tę rozmowę kilkadziesiąt razy.
Umów krótką rozmowę z nami. Opowiesz, co masz na biurku, my pokażemy, gdzie widzimy największe ryzyko i co warto przemyśleć, zanim coś podpiszesz lub wdrożysz.





