Modernizacja systemów legacy: playbook na 2026 rok

Jeśli to czytasz, pewnie masz system kluczowy dla Twojego biznesu – ale za każdym razem, gdy ktoś mówi „to tylko prosta zmiana”, Twój lead developer wygląda, jakby za chwilę miał zemdleć.
W świecie software’u nazywamy to legacy. Ten materiał to techniczno-strategiczny poradnik dla liderów, którzy chcą przestać jedynie żyć z długiem technologicznym i zacząć zarabiać dzięki technologii dobranej z głową.
Co to jest system legacy?
System legacy to istniejący system informatyczny, który wciąż działa (często jest kluczowy dla biznesu), ale trudno go rozwijać, drogo utrzymywać albo wiąże się z dużym ryzykiem zmian – bo opiera się na przestarzałej technologii, architekturze lub praktykach wytwarzania oprogramowania.
Czym jest modernizacja systemu legacy?
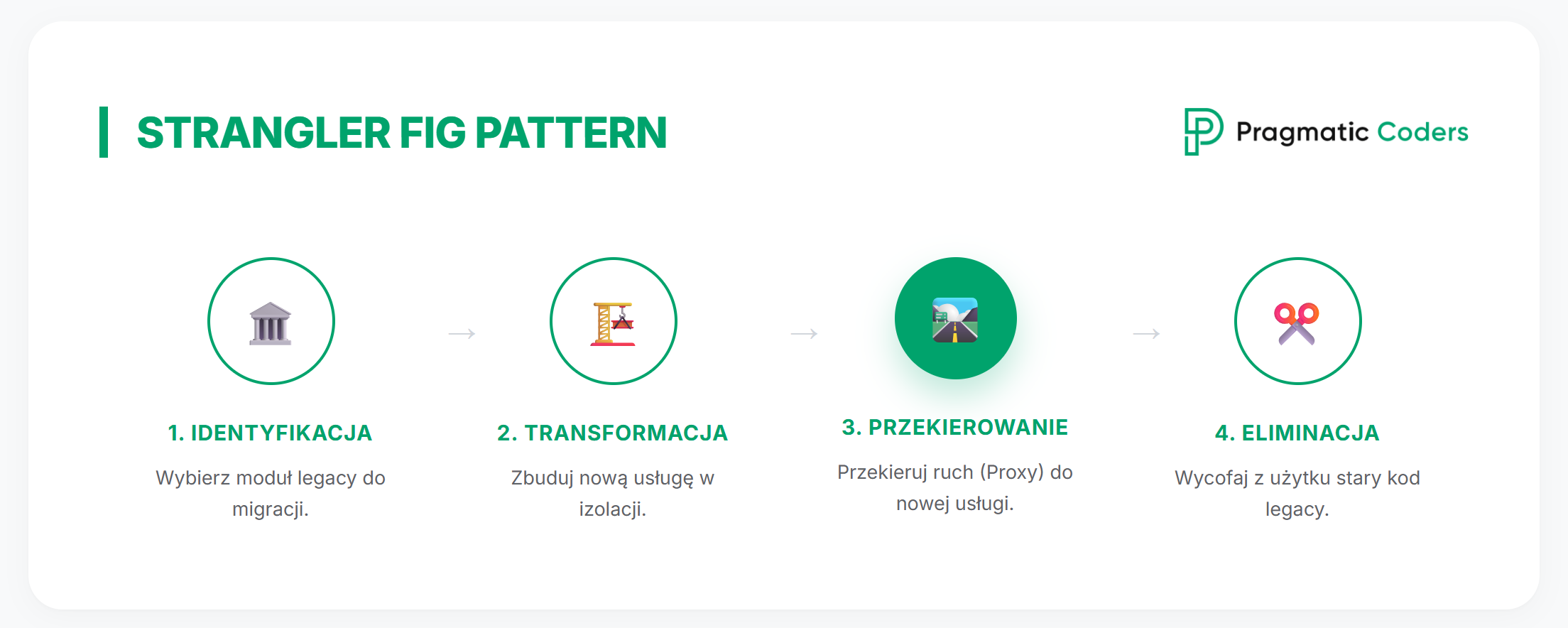
Modernizacja systemu legacy to zaplanowany proces usprawnienia istniejącego systemu tak, aby był łatwiejszy w rozwoju, tańszy w utrzymaniu i mniej ryzykowny – bez zatrzymywania biznesu. Zwykle obejmuje stopniowe zmiany w architekturze, kodzie, infrastrukturze i praktykach inżynieryjnych (np. testach, wdrożeniach, monitoringu), a nie tylko „przepisanie systemu od zera”.
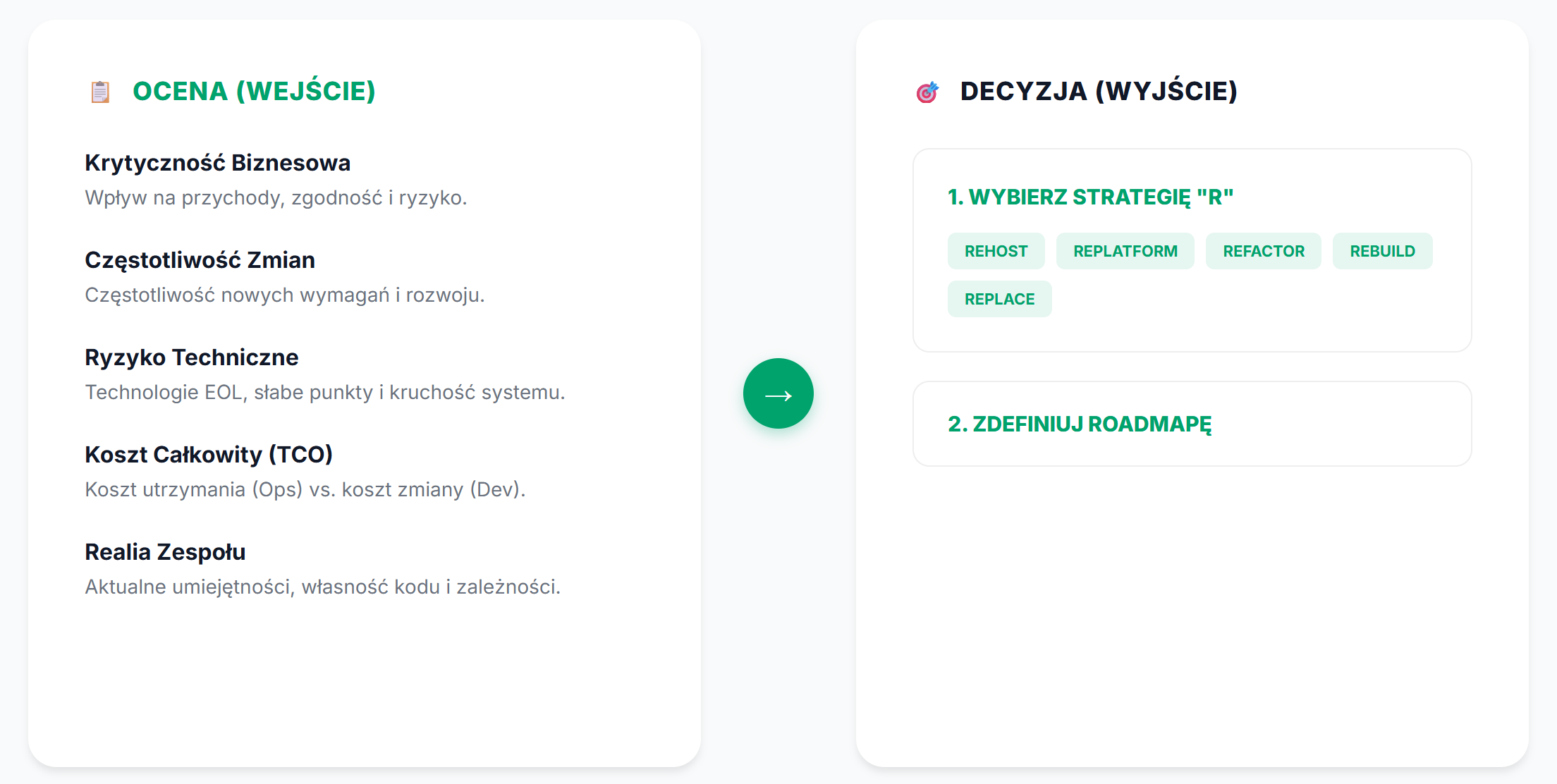
Modernizacja systemu legacy to jedna z usług, które my w Pragmatic Coders oferujemy w ramach naszych usług ratowania produktu:
- Stabilizacja / odzyskanie kontroli nad projektem
- Modernizacja
- Migracja do chmury
- Doskonałość platformy i inżynierii
- Dostarczanie produktu
Jaka jest różnica między modernizacją systemu legacy a modernizacją aplikacji?
Modernizacja systemu legacy oznacza unowocześnianie całego ekosystemu – aplikacji, danych, integracji, infrastruktury, procesów operacyjnych (monitoring, DR, CI/CD), a także bezpieczeństwa i ładu (governance).
Modernizacja aplikacji legacy dotyczy głównie samej aplikacji (albo zestawu aplikacji) – kodu, architektury, środowiska uruchomieniowego lub frameworka, API, czasem też wdrożeń. Nie musi obejmować przebudowy integracji w organizacji, strategii danych ani platformy.
W praktyce, ponieważ w wielu firmach „aplikacja” jest sercem całego „systemu”, granica między tymi pojęciami bywa rozmyta. Dodatkowo w dokumentacji dostawców oba terminy często są mieszane. W tym artykule będziemy więc używać ich zamiennie.
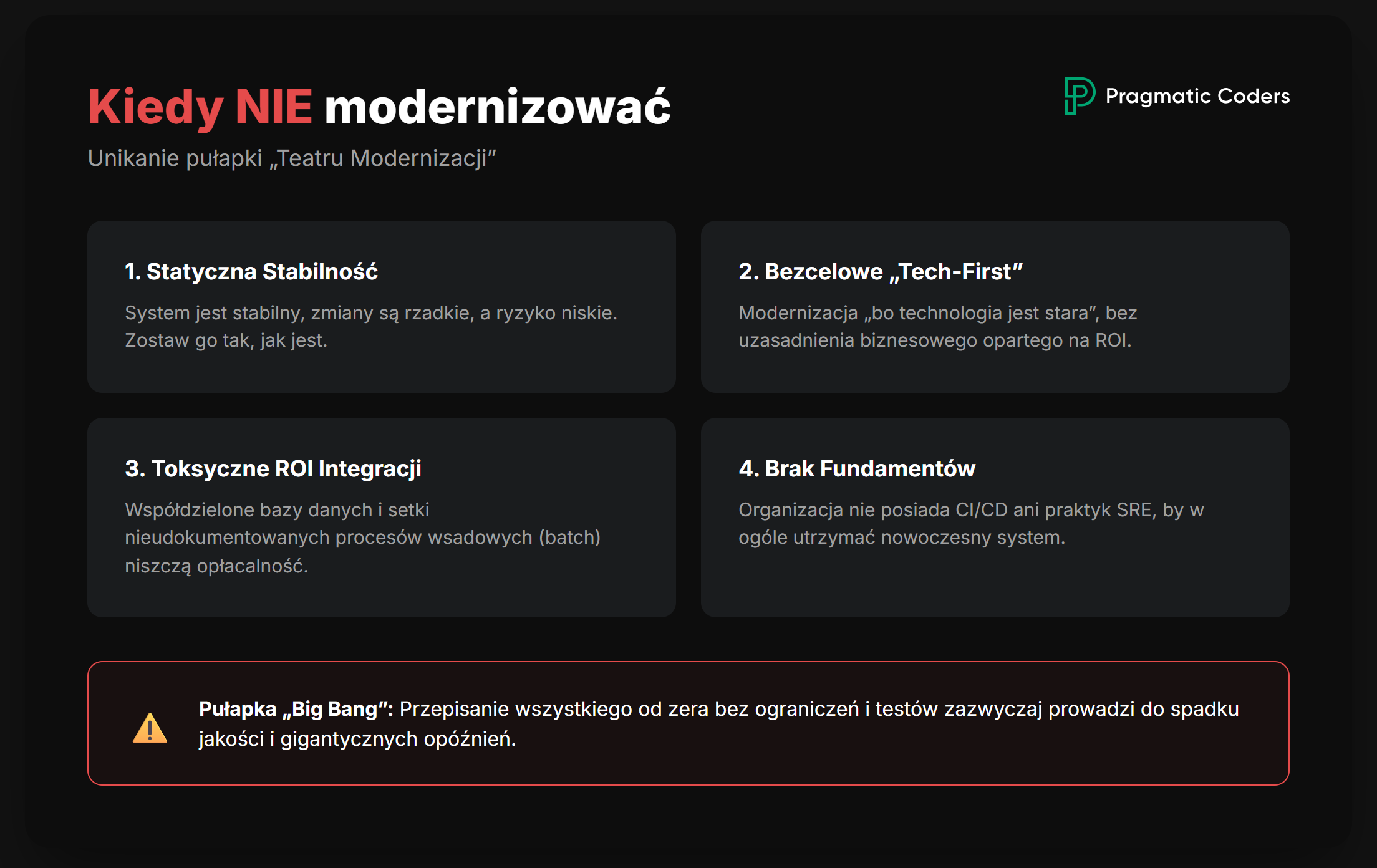
Why modernize legacy systems? And when not?
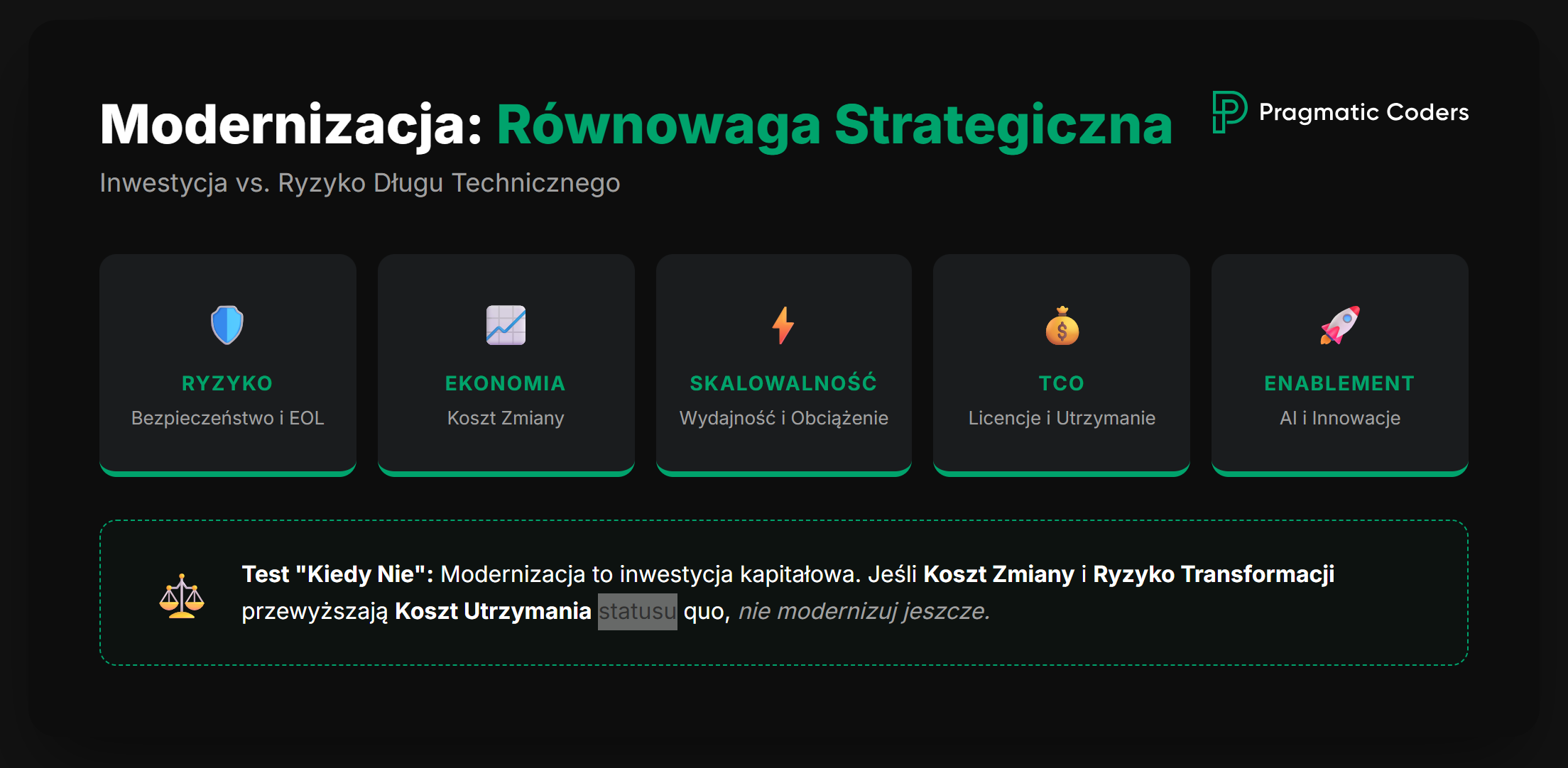
Nie zawsze się to opłaca. Modernizacja to inwestycja kapitałowa – w czas, ryzyko i koszt utraconych możliwości – więc ma sens tylko wtedy, gdy koszt i ryzyko dalszego utrzymywania systemu legacy są większe niż koszt i ryzyko jego zmiany. Zwykle bardziej opłaca się odzyskać kontrolę operacyjną nad starym systemem i przepisać tylko jego kluczowe części.
Modernizację robi się z kilku przyczyn:
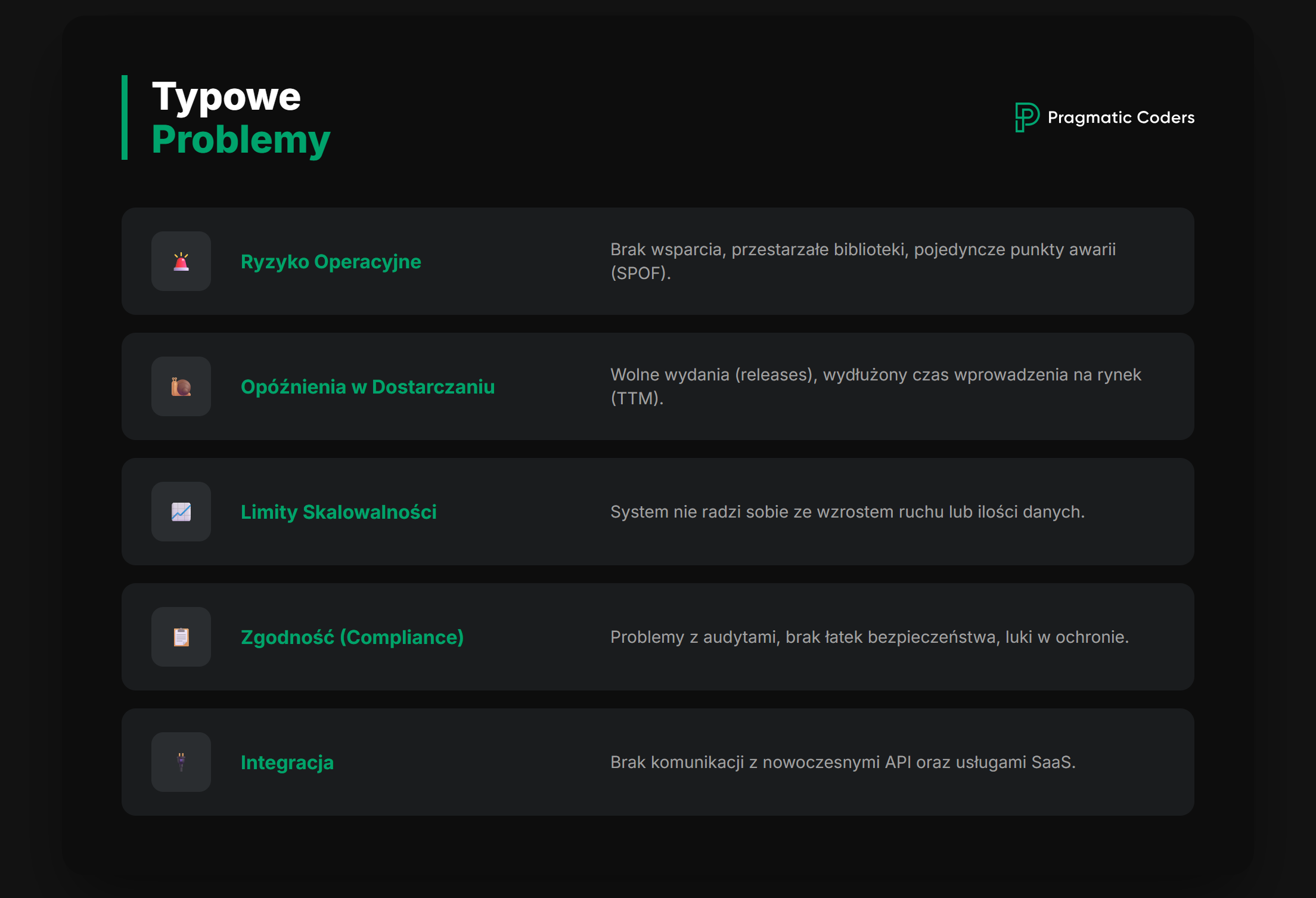
1.) Zarządzanie ryzykiem (najczęstszy „twardy” powód)
technologia “na końcu życia” (EOL) lub bez wsparcia – brak poprawek bezpieczeństwa
odchodzą kluczowe osoby („bus factor”)
awarie, słabe DR/BCP, brak obserwowalności
ryzyka zgodności (audyty, regulacje, dane)
Wartość: mniejsze prawdopodobieństwo kosztownej awarii lub incydentu.
2.) Ekonomia zmian (koszt wprowadzania zmian)
każda zmiana jest wolna i droga, bo system jest kruchy
wdrożenia są rzadkie, dużo regresji, „development oparty na strachu”
integracje to „Dziki Zachód” i blokują skalowanie
Wartość: krótszy lead time, częstsze wdrożenia, mniej rollbacków i hotfixów.
Modernizacja to nie tylko „czystszy kod” – chodzi o wynik finansowy. W przypadku Webinterpret wyszliśmy poza ograniczenia legacy i zbudowaliśmy system, który potrafi obsłużyć 10-krotny wzrost wolumenu danych, jednocześnie znacząco obniżając koszty infrastruktury.
Zobacz, jak skuteczna automatyzacja i modernizacja technologii przełożyły się na 800% wzrost liczby użytkowników.
WebInterpret: Skuteczna automatyzacja e-commerce – spadek liczby awarii o 99,97%
3.) Skalowalność / wydajność / doświadczenie klienta
system nie wyrabia w szczytach obciążenia
wydajność blokuje wzrost albo generuje koszty (np. licencje, infrastruktura)
4.) Koszty utrzymania (TCO) i vendor lock-in
drogie licencje, utrzymanie on-prem, ręczne operacje
brak automatyzacji, dużo „ops toil” (żmudnej pracy operacyjnej)
5.) Umożliwienie nowych inicjatyw
dane są „zamknięte”, brak API lub eventów, trudno szybko się integrować
chcesz wdrożyć AI/analitykę/nowe kanały sprzedaży, a system legacy jest „hamulcem”
Jeśli Twój system legacy działa jak hamulec dla wzrostu, musisz uniezależnić roadmapę od długu technologicznego. Nasze projekty w sektorze FoodTech pokazują, że ustabilizowanie kluczowej platformy pozwala firmie szybko skalować się i dostarczać nowe funkcje bez ciągłego strachu przed awariami.
Opisujemy, jak pomogliśmy startupowi FoodTech przejść z przestarzałego systemu dostawcy na skalowalną platformę stworzoną na zamówienie.
Jak przebudowa systemu pomogła startupowi FoodTech rosnąć szybciej